1. 이미지 탐지 종류
1) Classification (분류)
Classification은 가장 기본적인 이미지 처리 기법 중 하나입니다. 단어 그대로, 이미지를 특정 클래스 또는 카테고리로 분류하는 작업을 의미합니다. 주어진 이미지를 보고 이 이미지가 어떤 객체를 포함하고 있는지 결정하는 것이죠.

예시)
개, 고양이, 자동차와 같은 여러 카테고리가 있을 때, 이미지 속에 어떤 것이 있는지 맞추는 작업입니다. 예를 들어, 강아지 사진을 넣으면 '개'라는 클래스로 분류하는 것이 Classification입니다.
특징)
이미지를 전체적으로 보고 하나의 클래스만 예측
비교적 간단한 문제를 해결하는 데 적합
2) Object Detection (객체 탐지)
Object Detection은 한 단계 더 나아간 기술로, 이미지 내에서 여러 객체의 위치와 그 객체가 무엇인지까지 탐지하는 작업입니다. 이 기술은 이미지 속에 있는 여러 객체를 탐지하고, 그 위치를 바운딩 박스 (Bounding Box)로 표시합니다.

예시)
길거리 사진에서 사람, 자동차, 자전거 등을 찾아내고, 각 객체의 위치를 네모 박스로 둘러싸는 작업이 Object Detection입니다. 예를 들어, '여기에 사람이 있고, 여기에 자동차가 있다'는 정보를 제공하죠.
특징)
이미지를 분석하여 여러 객체를 탐지하고, 각 객체의 위치와 클래스(라벨)를 예측
자율주행 자동차, 보안 카메라 등에서 많이 사용
3) Semantic Segmentation (의미론적 분할)
Semantic Segmentation은 이미지의 각 픽셀을 특정 클래스에 할당하는 방식입니다. 한마디로, 이미지 내 모든 픽셀에 의미를 부여하는 작업이죠. 같은 클래스에 속하는 모든 픽셀은 동일한 라벨을 가집니다. 하지만 객체의 개별 인스턴스는 구분하지 않습니다.
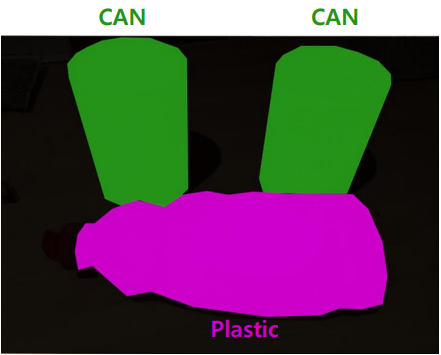
예시)
도시 이미지에서 도로, 건물, 하늘, 나무와 같은 픽셀을 각각의 카테고리로 분류합니다. 도로에 있는 모든 픽셀은 '도로'로, 하늘에 있는 모든 픽셀은 '하늘'로 라벨링하는 방식입니다.
특징)
이미지 내 모든 픽셀을 분류하지만, 객체의 개별 인스턴스는 구분하지 않습니다.
자율주행 자동차에서 도로와 인도, 차량을 구분하는 데 유용합니다.
4) Instance Segmentation (인스턴스 분할)
Instance Segmentation은 Object Detection과 Semantic Segmentation을 결합한 기술입니다. 이 방법은 객체의 위치를 탐지하면서, 픽셀 단위로 각 객체의 경계까지 구분합니다. 같은 클래스에 속하더라도, 각 객체의 개별 인스턴스를 정확하게 구분해내는 것이죠.

예시)
만약 사진에 여러 사람이 있다면, 각 사람을 개별적으로 구분하면서 동시에 픽셀 단위로 정확하게 사람의 경계를 그립니다. 여러 사람이 있어도 각각의 사람을 독립적으로 구분할 수 있는 것이 특징입니다.
특징)
객체의 개별 인스턴스를 구분하면서 픽셀 단위로 정확한 마스크를 생성합니다.
복잡한 이미지 처리 문제를 해결하는 데 적합하며, 의료 영상 분석이나 AR(증강현실)과 같은 분야에서 많이 사용됩니다.
2. Evaluation (평가) - 성능
Object Detection 에서는 성능과 속도를 평가로 사용합니다.
성능 - mAP
속도 - FPS, Flops
우선 mAP 개념을 이해하기 위해서 밑에의 개념을 알아야 합니다.
- Confusion matric
- Precision & Recall
- PR curve
- AP (Average Precision)
1) Confusion matric
Confusion Matrix는 분류 모델의 성능을 평가할 때 많이 사용되는 행렬로, 각 클래스에 대해 예측이 얼마나 잘 되었는지를 보여줍니다. 이를 통해 True Positive, True Negative, False Positive, False Negative를 확인할 수 있습니다.
- True Positive (TP): 모델이 정답이라고 예측한 것이 실제로도 정답인 경우
- True Negative (TN): 모델이 오답이라고 예측한 것이 실제로도 오답인 경우
- False Positive (FP): 모델이 정답이라고 예측했지만, 실제로는 오답인 경우
- False Negative (FN): 모델이 오답이라고 예측했지만, 실제로는 정답인 경우
예시)
예를 들어, 고양이와 개를 구분하는 모델에서 '고양이'를 고양이라고 잘 맞춘 경우는 TP,
고양이를 개라고 잘못 맞춘 경우는 FP로 기록됩니다.
기억하기 쉽게 짝을 지어서 생각하면 됩니다.
TP - FN
FP - TN
뒤에 붙어 있는 것이 모델이 예측한것 (P,N)
TP 의 경우 P의 의미는 모델이 정답이라고 예측 했고,
그것이 True 인것이다, 즉 정답인것!
FN 의 경우 N의 의미는 모델이 오답이라고 예측 했고,
그것이 Fasle 인것이다. 즉 정답인것!

2) Precision & Recall
Precision (정밀도)와 Recall (재현율)은 모델 성능을 평가할 때 자주 사용되는 두 가지 중요한 지표입니다.
- Precision (정밀도)
모델이 '정답'이라고 예측한 것 중에서 실제로 정답인 비율을 나타냅니다.
즉, 예측된 True Positive 중에서 얼마나 정확하게 예측되었는지 보는 것입니다.
모델의 예측 관점에서 말하는 것 입니다.

- Recall (재현율)
실제 정답인 것들 중에서 모델이 정답이라고 예측한 비율을 의미합니다.
즉, 전체 실제 정답 중에서 얼마나 많은 것을 찾아냈는지 확인하는 지표입니다.
정답의 모든 케이스 중에서 모델이 옳게 예측한게 어느정도 되나?

그림으로 예를 들어보겠습니다.

Precision
모델이 예측한 Box 8개 중에
총 4개를 예측 했음.
따라서 Precision = 4/8 = 0.5
Recall
정답 관점에서 총 5개의 GT(5개 라이터) 그 중에서 4개를 검출
따라서 RECALL 4/5 = 0.8
3) PR Curve (precision-recall curve)
- PR Curve 개념
PR Curve는 Precision과 Recall의 관계를 그래프로 표현한 것입니다. 모델의 다양한 임계값에서 Precision과 Recall의 변화를 보여주며, 모델의 성능을 시각적으로 평가하는 데 유용합니다. 보통 Precision-Recall Curve의 아래 면적이 클수록 좋은 모델로 평가합니다.
그래프를 해석 할때는,
오른쪽 위로 치우칠수록 모델이 Precision과 Recall을 모두 잘 균형 있게 맞춘다 즉, 성능이 매우 좋다는 의미입니다.
반대로 그래프가 아래로 쳐져 있다면, Precision 또는 Recall 중 하나가 낮다는 의미로 해석됩니다.
하지만,
모든 상황에서 Precision과 Recall을 완벽하게 맞추는 것이 필요한 것은 아니며,
어떤 문제에서는 한쪽 지표를 더 중요하게 생각할 수 있습니다. 이를 구체적으로 설명하면
- Precision이 중요한 경우: 잘못된 예측(오탐, False Positives)을 최소화하는 것이 목표일 때, 예를 들어 의료 진단에서 질병이 없는데도 질병이 있다고 잘못 진단하면 큰 문제가 발생할 수 있습니다. 이런 경우 Precision을 높이는 것이 더 중요합니다.
- Recall이 중요한 경우: 가능한 한 많은 정답을 놓치지 않는 것이 중요한 상황에서는 Recall을 우선해야 합니다. 예를 들어, 보안 카메라에서 위험 요소를 탐지하는 시스템이라면, 위험한 상황을 빠짐없이 탐지하는 것이 중요하므로 Recall이 더 중요할 수 있습니다.
결론적으로, Precision과 Recall을 모두 높은 수준에서 맞추는 것이 이상적이지만, 상황에 따라 어떤 지표를 더 중요하게 여길지는 문제에 따라 다릅니다. 따라서, 모델이 해결하려는 문제의 특성을 고려하여 두 지표 간의 균형을 맞추는 것이 중요합니다.
- PR Curve 그래프 산출 방법
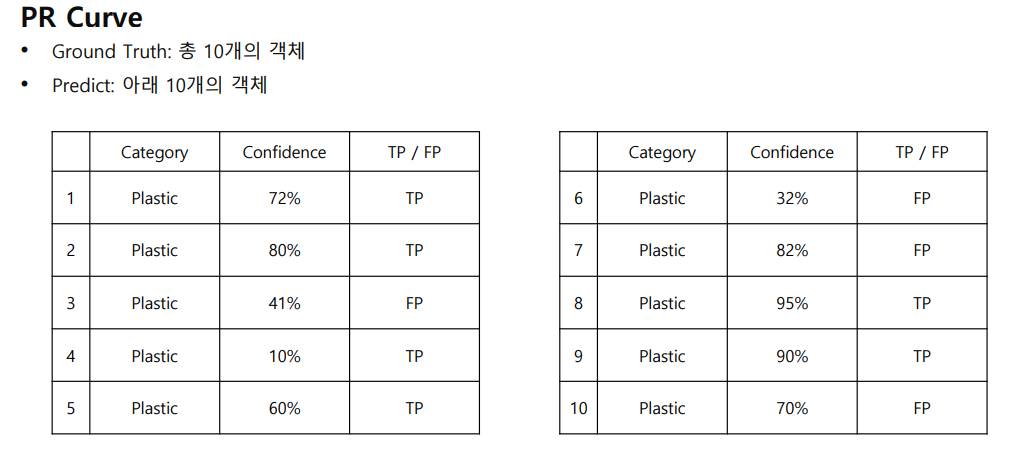
위의 표시 Plastic 예측한 예시 결과이다.
우선 Confidence 를 기준으로 내림차순을 하고,
이때 precision, recall 를 누적으로 구할 수 있다.
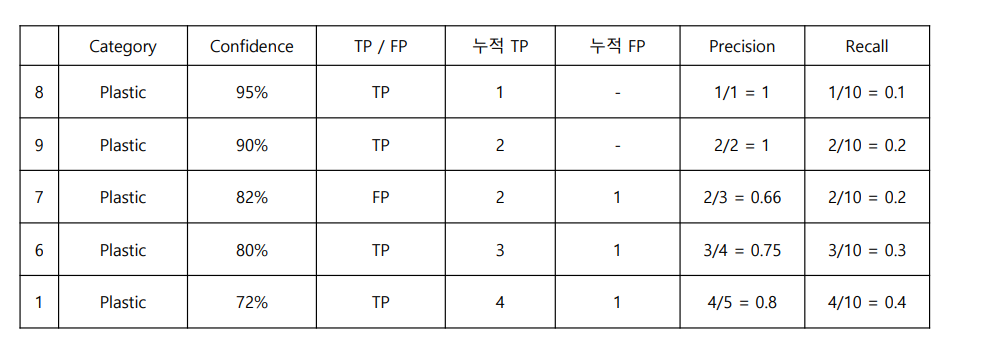

누적 TP, 누적 FP 기반으로 precsion, recall 를 구할 수 있다.
이것를 기반으로 (0.1, 1) (recall, precsion) 좌표 기반으로 그래프를 아래와 같이 그릴 수 있다.

위와 같이 그래프를 그리면 PR curve 그래프가 완성된다.
4) AP (average precsion)
AP (Average Precision)는 모델이 하나의 클래스에 대해 얼마나 정확하게 예측했는지를 평가하는 지표입니다.
PR Curve에서 Recall 축을 기준으로 Precision 값을 적분한 면적이 AP 값입니다. 각 클래스마다 AP를 계산할 수 있으며, 이 AP의 평균을 낸 값이 mAP가 됩니다.
예시)
특정 클래스에서 모델의 Precision과 Recall 값을 통해 얻은 PR Curve의 면적이 클수록
해당 클래스의 AP 값이 높아집니다.

각 클래스별로 AP 를 구하고, 평균을 구하면 mAP 가 된다.


AP (Average Precision)의 면적이 크다는 것은 모델의 Precision과 Recall이 높은 값을 유지하면서, 둘 간의 균형이 잘 맞는다는 것을 의미합니다. AP는 Precision-Recall 곡선의 아래쪽 면적을 계산한 값인데, 면적이 클수록 다음과 같은 의미를 가집니다:
- Precision이 높다: 모델이 예측한 결과 중에서 올바르게 예측된 비율이 높습니다.
즉, 잘못된 예측(오탐, False Positives)이 적다는 뜻입니다. - Recall이 높다: 모델이 실제로 존재하는 정답(객체)을 많이 탐지했습니다.
즉, 놓친 정답(누락, False Negatives)이 적다는 의미입니다. - Precision과 Recall의 균형이 좋다: AP의 면적이 크면, 모델이 Precision과 Recall 모두에서 높은 성능을 유지하고 있음을 보여줍니다. 즉, 모델이 잘못된 예측을 적게 하면서도 많은 객체를 탐지하는 능력이 뛰어나다는 뜻입니다.
더 구체적으로 설명하면
- 면적이 크다는 것은 Precision이 어느 한쪽 값(Recall이 매우 낮은 지점이나 매우 높은 지점)에서만 높지 않고, 여러 Recall 값에 걸쳐 균형 있게 높은 Precision을 유지한다는 것을 의미합니다.
- 면적이 작다면: 이는 모델이 특정 구간에서 Precision이 떨어진다는 의미일 수 있으며, 이는 모델이 잘못된 탐지를 많이 하거나(Precision 저하) 많은 객체를 놓치고 있을 가능성(Recall 저하)이 높습니다.
따라서 AP 면적이 크다는 것은 모델의 전체적인 성능이 좋다는 지표로 해석할 수 있습니다. 특히 객체 탐지 문제에서는 AP를 높게 유지하는 것이 매우 중요하며, 이를 바탕으로 mAP (mean Average Precision) 값이 계산됩니다.
5) IOU (Intersection Over Union)
classfication 은 True, False 가 명확한데, Decticion 의 경우는 다릅니다.
IOU 는 예측된 바운딩 박스(bbox)가 실제 바운딩 박스와 얼마나 겹치는지를 측정하는 지표입니다. 두 바운딩 박스가 겹치는 영역을 합집합 영역으로 나누어 계산하며, IOU 값이 1에 가까울수록 모델이 정확하게 객체의 위치를 예측한 것입니다.

예시를 보면 더 쉽게 이해가 되는데,
IOU 는 모델이 예측한 bbox가 정답 bbox랑 얼마나 겹쳤는지 확인하는 것입니다.

위의 이미지와 같이 IOU 는 우리가 정한 값에 따라 TP, FP가 될 수 있습니다.
앞으로 mAP50 이라는 말은 mAP + lou 0.5 이상이면 T, 이하이면 F 이다. 라고 했을때, 그때 mAP 가 어찌 되는가??
이것이 성능 평가의 지표로 사용 됩니다.
3. Evaluation (평가) - 속도
1) FPS (Frames Per Second)

FPS는 Frames Per Second의 약자로, 모델이 1초 동안 처리할 수 있는 프레임(이미지)의 개수를 의미합니다. 주로 실시간 성능이 중요한 컴퓨터 비전 작업(예: 객체 탐지, 영상 처리)에서 모델의 속도를 평가하는 지표로 사용됩니다.
- 높은 FPS: 모델이 이미지를 매우 빠르게 처리할 수 있다는 의미입니다. 예를 들어, FPS가 30이면 1초에 30개의 이미지를 처리할 수 있다는 뜻입니다. 실시간 시스템(예: 자율주행, CCTV 분석)에서는 보통 30 FPS 이상의 속도를 요구합니다.
- 낮은 FPS: 모델이 이미지를 처리하는 속도가 느리다는 의미입니다. 실시간 시스템에서는 이러한 모델을 사용할 경우, 처리 지연이 발생할 수 있습니다.
FPS가 중요한 이유
- 실시간성: FPS는 특히 실시간 어플리케이션에서 중요합니다. 예를 들어, 자율주행 차량에서는 차량 주변 상황을 빠르게 인식해야 하기 때문에 높은 FPS가 필수입니다.
- 시스템 효율성: 영상 분석 시스템에서 높은 FPS는 빠른 처리 속도를 의미하며, 시스템의 처리 효율성을 증가시킵니다.
2) FLOPs ( Floating Point Operations per Second)
FLOPs는 Floating Point Operations per Second의 약자로, 모델이 1초 동안 처리할 수 있는 부동소수점 연산(floating point operations)의 개수를 나타냅니다. 이것은 모델의 연산 복잡도를 나타내는 지표입니다. FLOPs는 보통 모델의 크기나 복잡도, 그리고 성능을 평가하는데 사용됩니다.
- 높은 FLOPs: 모델이 복잡한 연산을 많이 수행한다는 의미입니다. 연산이 많다는 것은 일반적으로 모델이 복잡하고, 더 정확한 예측을 할 가능성이 있지만 그만큼 연산량이 많아서 처리 속도는 느려질 수 있습니다.
- 낮은 FLOPs: 모델이 비교적 적은 연산을 수행하며, 그만큼 빠르게 처리할 수 있다는 의미입니다. 다만 연산량이 적으면 모델의 성능이나 예측 정확도가 떨어질 수 있습니다.
FLOPs가 중요한 이유:
- 연산 효율성: FLOPs는 모델이 얼마나 많은 연산을 필요로 하는지 평가하는 데 중요한 역할을 합니다. 이를 통해 모델이 얼마나 효율적으로 자원을 사용하는지를 판단할 수 있습니다.
- 모델 비교: FLOPs는 두 모델의 복잡도를 비교할 때 유용합니다. 예를 들어, 두 모델의 성능이 비슷할 경우 FLOPs가 적은 모델이 더 효율적인 모델이라고 볼 수 있습니다.
- 하드웨어 요구사항: 모델이 얼마나 많은 연산을 요구하는지에 따라, 이를 실행할 수 있는 하드웨어의 성능 요구사항도 달라집니다. FLOPs가 높으면 더 강력한 GPU나 CPU가 필요합니다.
- 연산량 계산방법 예시
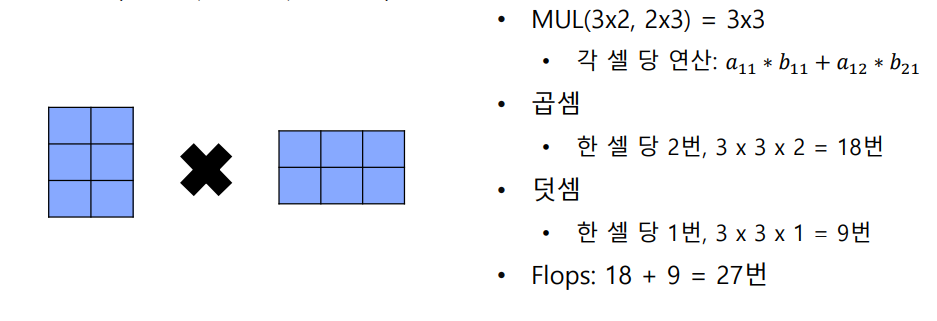
예시: 행렬 곱셈 (MUL 3x2, 2x3):
이미지에서는 3x2 행렬과 2x3 행렬의 곱셈 예시를 보여줍니다. 이 곱셈의 결과는 3x3 행렬이 됩니다.
각 셀(행렬의 원소)에서는 곱셈과 덧셈이 일어나며, 구체적으로 다음과 같은 연산들이 수행됩니다:
- 곱셈 연산: 각 셀 당 2번의 곱셈이 발생하며, 3x3x2 = 총 18번의 곱셈 연산이 일어납니다.
- 덧셈 연산: 각 셀 당 1번의 덧셈이 발생하며, 3x3x1 = 총 9번의 덧셈 연산이 일어납니다.
FLOPs 계산:
- 곱셈 연산과 덧셈 연산을 합치면, 총 27번의 FLOPs가 발생한 것으로 계산됩니다. 즉, 이 행렬 곱셈에서 발생한 부동 소수점 연산의 총 횟수는 27입니다.
- 이처럼 FLOPs는 연산 복잡도를 계산하는 데 사용되며, 모델이 처리해야 하는 총 연산량을 나타냅니다. 연산량이 많을수록 더 많은 자원이 필요하며, 처리 시간이 늘어날 수 있습니다.
이제까지 Object detection 이 어떻게 평가하는지 살펴 보았습니다.
긴 글 읽어주셔서 감사합니다.
'딥러닝 (Deep Learning) > [06] - 평가 및 결과 분석' 카테고리의 다른 글
| Ensemble 종류와 특징 (4) | 2024.11.16 |
|---|---|
| Class Activation Mapping (CAM)과 Grad-CAM (1) | 2024.08.29 |
| ZFNet 딥러닝 모델 시각화와 데이터 증강(Augumentation) 이해 (3) | 2024.08.29 |