Ensemble 이란?
Ensemble이란 여러 개의 모델을 조합하여 단일 모델보다 더 나은 성능을 달성하려는 기법을 말한다. 머신러닝 및 딥러닝에서, 서로 다른 모델이나 같은 구조의 모델을 조합하면 단일 모델의 한계를 보완하고, 더 일반화된 예측 성능을 얻을 수 있다.
Segmentation에서 ensemble을 활용하면 서로 다른 모델의 예측 결과를 조합하여 성능을 향상시킬 수 있다.
이번 글은 segmentation에 사용할 수 있는 ensemble 기법들을 소개하겠다.
기본 Ensemble
1. Majority Voting (Pixel-wise Voting)
Majority Voting (Pixel-wise Voting)는 Segmentation 작업에서 각 픽셀 단위로 여러 모델의 출력 결과를 조합하여 다수결로 최종 클래스를 결정하는 방법이다. 이 방법은 각 모델이 독립적으로 예측한 결과를 비교하고, 해당 픽셀 위치에서 가장 많이 나온 클래스를 최종 출력으로 선택한다.
작동 원리
- 여러 모델이 동일한 입력 이미지에 대해 각자 Segmentation 마스크를 출력
- 각 픽셀 위치에서 모든 모델의 출력 값을 수집
- 특정 픽셀 위치에서 가장 많이 등장한 클래스를 최종 픽셀 값으로 설정
import numpy as np
from scipy.stats import mode
def majority_voting(predictions):
"""
다수결 투표를 통한 세그멘테이션 마스크 결합.
Args:
predictions (list of np.array): 여러 모델의 세그멘테이션 마스크 예측 리스트.
각 마스크는 (H, W) 형태입니다.
Returns:
np.array: 다수결 투표 후 최종 세그멘테이션 마스크 (H, W) 형태.
"""
# 각 모델의 예측 마스크를 새로운 축으로 쌓아 (N, H, W) 형태의 배열 생성
stacked_predictions = np.stack(predictions, axis=0) # 형태: (N, H, W)
# 첫 번째 축(N)을 기준으로 다수결 투표 수행
final_mask, _ = mode(stacked_predictions, axis=0)
# 불필요한 차원 제거하여 (H, W) 형태로 반환
return final_mask.squeeze()
# 예제 사용법
if __name__ == "__main__":
# 3개의 모델로부터 생성된 가상의 4x4 세그멘테이션 마스크 예측 값
model_1 = np.array([[1, 0, 1, 2],
[0, 1, 1, 1],
[2, 2, 0, 0],
[1, 1, 2, 0]])
model_2 = np.array([[1, 1, 1, 2],
[0, 1, 0, 1],
[2, 0, 0, 0],
[1, 1, 2, 2]])
model_3 = np.array([[1, 0, 1, 2],
[0, 0, 1, 1],
[2, 2, 0, 1],
[1, 1, 2, 0]])
# 예측 마스크들을 리스트로 묶음
predictions = [model_1, model_2, model_3]
# 다수결 투표 수행
final_mask = majority_voting(predictions)
print("다수결 투표 후 최종 세그멘테이션 마스크:")
print(final_mask)
# 다수결 투표 결과
[[1, 0, 1, 2],
[0, 1, 1, 1],
[2, 2, 0, 0],
[1, 1, 2, 0]]
장점
구현이 간단하며, 모델 간의 균형이 맞으면 효과적
모델의 다양성을 활용할 수 있음
단점
모델의 성능 차이가 큰 경우, 성능이 낮은 모델이 결과를 방해할 수 있음
클래스 간 불균형 문제 발생 가능
2. Weighted Voting
Weighted Voting은 앙상블을 구성하는 여러 모델의 성능에 따라 각 모델에 가중치를 부여하여 최종 출력을 생성하는 방법이다. 예를 들어, F1-score나 IoU(Intersection over Union) 같은 평가 지표를 통해 모델의 성능을 측정하고, 그 성능에 비례하여 가중치를 부여할 수 있다. 성능이 더 높은 모델의 예측 결과가 최종 결과에 더 큰 영향을 미치게 된다.
작동원리
- 각 모델의 성능을 미리 평가하여 가중치를 설정한다.
- 각 모델의 출력 마스크에 해당 가중치를 곱한다.
- 모든 모델의 가중치가 적용된 마스크를 더한 후, 최종 마스크를 생성한다.
import numpy as np
def weighted_voting(predictions, weights):
"""
가중치 투표를 통한 세그멘테이션 마스크 결합.
Args:
predictions (list of np.array): 여러 모델의 세그멘테이션 마스크 예측 리스트.
각 마스크는 (H, W) 형태입니다.
weights (list of float): 각 모델의 성능에 따라 부여된 가중치 리스트.
Returns:
np.array: 가중치 투표 후 최종 세그멘테이션 마스크 (H, W) 형태.
"""
# 가중치 합이 1이 되도록 정규화
weights = np.array(weights) / np.sum(weights)
# 가중치를 곱하여 예측값을 합산
weighted_sum = np.sum([pred * weight for pred, weight in zip(predictions, weights)], axis=0)
# Threshold 적용하여 최종 마스크 생성 (여기서는 0.5 기준으로 이진화)
final_mask = (weighted_sum >= 0.5).astype(int)
return final_mask
# 예제 사용법
if __name__ == "__main__":
# 가상의 세그멘테이션 마스크 (4x4 크기, 이진 클래스 예시)
model_1 = np.array([[1, 0, 1, 1],
[0, 1, 1, 0],
[1, 0, 0, 1],
[0, 1, 1, 1]])
model_2 = np.array([[1, 1, 1, 0],
[0, 1, 1, 1],
[1, 0, 0, 0],
[0, 1, 1, 0]])
model_3 = np.array([[1, 0, 0, 1],
[1, 1, 1, 1],
[1, 1, 0, 1],
[0, 0, 1, 1]])
# 예측 마스크 리스트로 결합
predictions = [model_1, model_2, model_3]
# 각 모델의 성능에 따른 가중치 (예: F1-score 또는 IoU 기반)
weights = [0.5, 0.3, 0.2] # 성능이 좋은 모델에 더 높은 가중치
# 가중치 투표 수행
final_mask = weighted_voting(predictions, weights)
print("가중치 투표 후 최종 세그멘테이션 마스크:")
print(final_mask)
장점
성능 높은 모델 반영: 성능이 좋은 모델의 예측이 더 큰 영향을 미치므로, 전반적으로 성능이 높은 모델의 강점을 활용할 수 있다.
잘못된 모델의 영향 감소: 성능이 낮은 모델에 낮은 가중치를 부여하여, 모델의 성능이 크게 차이 나는 경우에도 상대적으로 높은 성능을 얻을 수 있다.
유연한 조정 가능: 가중치를 성능 지표(F1-Score, IoU 등) 또는 실험 결과에 따라 조정할 수 있어, 데이터셋에 맞게 최적화된 조합을 만들 수 있다.
단점
가중치 설정의 복잡성: 각 모델의 가중치를 결정하는 과정이 복잡할 수 있다. 모델 성능에 따라 최적의 가중치를 찾아야 하기 때문에, 별도의 성능 평가와 실험이 필요할 수 있다.
모델 간의 균형 중요: 가중치가 잘못 설정되면 오히려 성능이 떨어질 수 있다. 성능이 낮은 모델에 높은 가중치를 부여하면, 최종 결과에 부정적인 영향을 미칠 수 있다.
3. Averaging Outputs (Soft Voting)
Averaging Outputs 또는 Soft Voting은 각 모델의 출력 값을 평균 내어 최종 출력을 생성하는 방법이다. 일반적으로 다중 클래스 예측에서 확률 값(logits)을 사용하며, 각 모델의 예측 확률을 평균한 후 argmax를 적용하여 최종 클래스를 결정한다. 이 방법은 모델 간의 예측이 유사할수록 더 높은 성능을 기대할 수 있다.
작동원리
- 각 모델의 출력 값을 같은 위치의 확률로 평균을 계산한다.
- 평균 결과에서 argmax를 통해 최종 클래스를 선택한다.
import numpy as np
def soft_voting(predictions):
"""
Soft voting을 통한 세그멘테이션 마스크 결합 (평균화 방식).
Args:
predictions (list of np.array): 여러 모델의 세그멘테이션 마스크 예측 (logits) 리스트.
각 마스크는 (H, W, C) 형태이고, C는 클래스 수입니다.
Returns:
np.array: Soft voting 후 최종 세그멘테이션 마스크 (H, W) 형태.
"""
# 모든 모델의 예측값을 평균화
averaged_output = np.mean(predictions, axis=0) # 형태: (H, W, C)
# 클래스 축에서 argmax를 통해 최종 클래스 예측
final_mask = np.argmax(averaged_output, axis=-1)
return final_mask
# 예제 사용법
if __name__ == "__main__":
# 가상의 세그멘테이션 마스크 (4x4 크기, 3개 클래스 예시)
model_1 = np.array([[[0.1, 0.8, 0.1], [0.7, 0.2, 0.1], [0.6, 0.3, 0.1], [0.2, 0.5, 0.3]],
[[0.3, 0.6, 0.1], [0.8, 0.1, 0.1], [0.7, 0.1, 0.2], [0.2, 0.7, 0.1]],
[[0.1, 0.5, 0.4], [0.3, 0.3, 0.4], [0.6, 0.2, 0.2], [0.3, 0.5, 0.2]],
[[0.5, 0.2, 0.3], [0.2, 0.7, 0.1], [0.4, 0.4, 0.2], [0.3, 0.5, 0.2]]])
model_2 = np.array([[[0.2, 0.6, 0.2], [0.6, 0.3, 0.1], [0.5, 0.4, 0.1], [0.3, 0.6, 0.1]],
[[0.4, 0.5, 0.1], [0.7, 0.2, 0.1], [0.6, 0.2, 0.2], [0.3, 0.6, 0.1]],
[[0.2, 0.6, 0.2], [0.3, 0.4, 0.3], [0.5, 0.3, 0.2], [0.4, 0.4, 0.2]],
[[0.4, 0.3, 0.3], [0.3, 0.6, 0.1], [0.5, 0.3, 0.2], [0.3, 0.5, 0.2]]])
model_3 = np.array([[[0.3, 0.5, 0.2], [0.5, 0.4, 0.1], [0.4, 0.5, 0.1], [0.2, 0.7, 0.1]],
[[0.5, 0.4, 0.1], [0.6, 0.3, 0.1], [0.5, 0.3, 0.2], [0.4, 0.5, 0.1]],
[[0.3, 0.4, 0.3], [0.2, 0.5, 0.3], [0.4, 0.4, 0.2], [0.5, 0.3, 0.2]],
[[0.3, 0.5, 0.2], [0.2, 0.6, 0.2], [0.3, 0.6, 0.1], [0.4, 0.4, 0.2]]])
# 예측 마스크 리스트로 결합
predictions = [model_1, model_2, model_3]
# Soft voting 수행
final_mask = soft_voting(predictions)
print("Soft Voting 후 최종 세그멘테이션 마스크:")
print(final_mask)
장점
간단한 구현: 각 모델의 예측값을 평균하여 최종 결과를 만드는 방식이기 때문에, 구현이 간단하고 직관적이다.
모델의 균형 반영: 모든 모델의 예측 결과를 동일한 비중으로 취급하기 때문에, 특정 모델에 성능이 편향되지 않고 균형 잡힌 예측을 생성할 수 있다.
일관된 성능: 모든 모델의 예측이 유사할 경우, 평균화하여 성능을 안정적으로 유지할 수 있습니다. 모델 간의 예측이 크게 다르지 않은 경우 유리하다.
단점
모델 성능의 반영 부족: 모든 모델의 예측이 동일한 비중으로 반영되므로, 성능이 좋은 모델과 낮은 모델을 차별화하지 않습니다. 성능이 낮은 모델이 최종 예측에 부정적인 영향을 줄 수 있다.
성능 편차가 큰 경우 비효율적: 모델 성능이 일정하지 않고 편차가 큰 경우, 성능이 낮은 모델의 영향으로 최종 예측 성능이 떨어질 수 있다.
다중 클래스 예측에서 제한: 다중 클래스 예측에서 특정 클래스가 다수 등장하지 않는 경우, 평균화 과정에서 확률이 희석될 수 있어 정확도가 떨어질 수 있다.
확장 Ensemble
1. Seed Ensemble
Seed Ensemble은 모델 학습 시 랜덤 시드만 다르게 설정하여 여러 모델을 학습시키고, 그 결과를 앙상블하는 기법이다. 머신러닝이나 딥러닝 모델을 학습할 때, 랜덤 시드 값에 따라 학습 결과가 조금씩 달라질 수 있다. Seed Ensemble은 이 특성을 이용하여 다양한 시드 값으로 모델을 학습하고, 그 결과를 결합하여 최종 예측 성능을 향상시키는 방법이다.
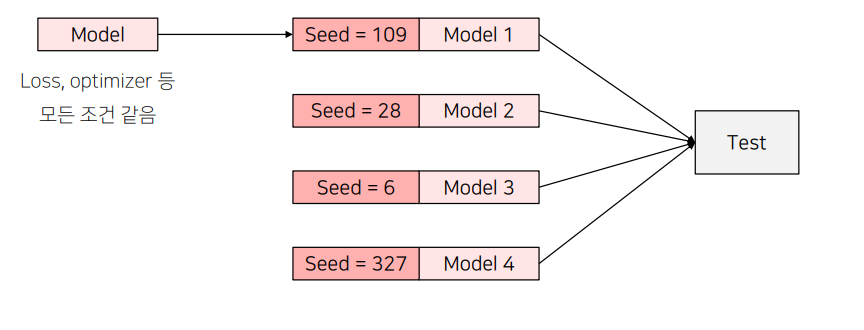
Seed Ensemble은 위의 그림에서 쉽게 이해 할 수 있다.
- 랜덤 시드 설정: 랜덤 시드 값은 모델 학습 시 초기화되는 가중치, 데이터 셔플링, 배치 구성 등에서 영향을 미치는 요소이다. 같은 모델 구조와 하이퍼파라미터를 사용하더라도, 랜덤 시드를 다르게 설정하면 모델이 학습하는 경로가 달라지게 된다.
- 여러 모델 학습: 동일한 모델 구조, 하이퍼파라미터, 데이터셋을 사용하고 랜덤 시드 값만 다르게 설정하여 여러 개의 모델을 학습시킨다. 그림에서는 시드 값으로 109, 28, 6, 327을 사용한 예시가 있다.
- 예측 결합: 학습된 여러 모델의 예측 결과를 결합하여 최종 예측을 생성한다. 결합 방법으로는 Pixel-wise Voting, Averaging, Weighted Voting 등이 있으며, 일반적으로 다수결 투표(Pixel-wise Voting)를 사용한다.
2. Multi-scale Ensemble
이미지 분류나 객체 탐지, 세그멘테이션 등에서 모델의 성능을 향상시키기 위해 앙상블 기법을 자주 활용한다. 이 중 Multi-scale Ensemble은 동일한 모델을 사용하되, 서로 다른 해상도의 이미지를 입력으로 넣어 앙상블을 수행하는 방법이다. 이미지 크기를 다양하게 변형하여 입력함으로써, 모델이 이미지의 다양한 스케일(크기)에서 정보를 학습하고 예측하도록 도와준다.
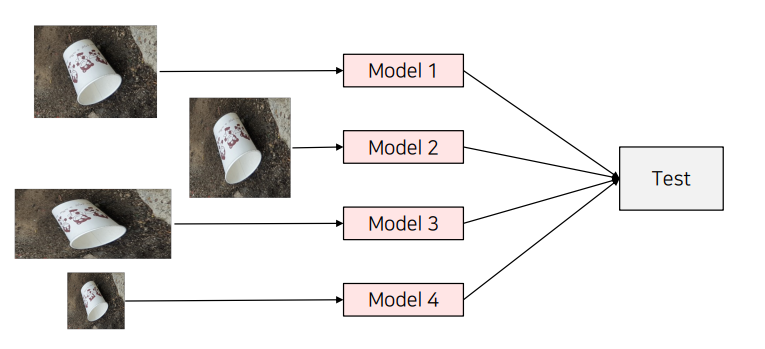
위의 그림처럼 같은 이미지를 서로 다른 크기로 조정하여 모델에 입력하고, 각 해상도에서 얻은 예측 결과를 결합하여 최종 예측을 도출하는 방식이다.
- 서로 다른 해상도로 이미지 생성: 원본 이미지를 여러 크기로 변형하여 준비한다. 예를 들어, 원본 이미지와 함께 더 작거나 큰 이미지를 생성한다.
- 모델에 각각의 이미지 입력: 변형된 각 이미지를 동일한 모델에 입력하여 예측 결과를 얻는다.
- 결과 결합: 여러 해상도에서 얻은 예측 결과를 앙상블하여 최종 결과를 만든다. 결합 방식으로는 다수결 투표(Majority Voting), Soft Voting, Weighted Voting 등을 사용할 수 있다.
3. TTA (Test Time Augmentation)
TTA(Test Time Augmentation)은 모델이 테스트 시에도 다양한 데이터 증강을 적용하여 성능을 향상시키는 방법이다. 일반적으로 데이터 증강(Augmentation)은 학습 단계에서만 적용되지만, TTA는 테스트 단계에서도 증강을 수행하여 모델의 예측 결과를 더욱 일반화시키고, 성능을 높이는 데 목적이 있다. 이는 특히 이미지 분류, 객체 탐지, 세그멘테이션 등 다양한 컴퓨터 비전 과제에서 사용된다.
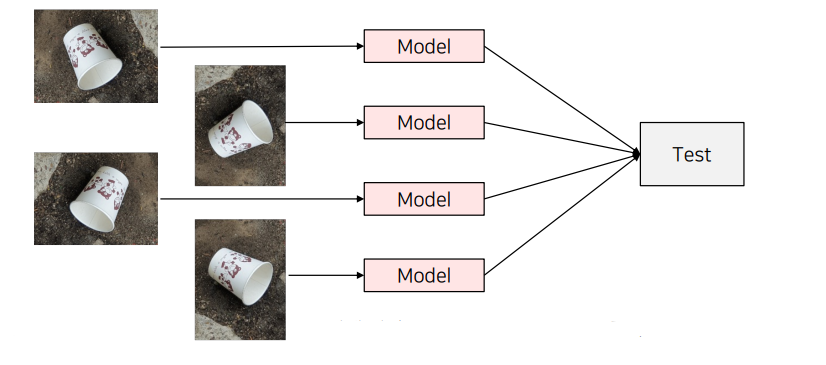
TTA 수행 과정
- 원본 이미지 및 증강된 이미지 생성: 원본 이미지를 여러 증강 기법을 적용하여 여러 개의 테스트 이미지를 생성한다.
- 모델에 각 이미지 입력: 원본 이미지와 증강된 이미지들을 동일한 모델에 각각 입력하여 예측 결과를 얻는다.
- 결과 결합: 모든 예측 결과를 결합하여 최종 예측을 생성한다. 이때, Soft Voting(평균화), Majority Voting(다수결) 등의 방법을 사용할 수 있다.
장단점
장점
일관된 성능 확보: 다양한 증강을 통해 여러 버전의 이미지를 테스트하므로, 모델이 원본 이미지의 불확실성을 보완하고 더욱 일관된 성능을 제공할 수 있다.
일반화 성능 향상: 테스트 시에도 증강을 수행함으로써 모델이 다양한 조건에서 잘 작동하도록 만들어, 일반화 성능이 향상될 수 있다.
적응력 강화: 테스트 이미지가 학습 이미지와 다른 조건을 가지더라도, 다양한 증강을 통해 모델이 이를 인식하고 더 나은 예측을 수행할 수 있다.
단점
추가적인 계산 비용: 테스트 시 증강된 이미지들을 여러 번 모델에 입력해야 하므로, 일반적인 테스트보다 계산 비용이 높아진다.
증강 선택의 어려움: TTA에서 어떤 증강을 사용할지에 따라 성능 차이가 발생할 수 있다. 최적의 증강 조합을 찾기 위해 여러 실험이 필요할 수 있다.
과적합 위험: 잘못된 증강 기법을 사용하면 오히려 모델이 특정 패턴에 과적합될 위험이 있다.
TTA Library - ttach
ttach는 Test Time Augmentation (TTA)를 쉽게 구현할 수 있도록 도와주는 파이썬 라이브러리이다.
import ttach as tta
# TTA 증강 설정
# Compose 객체를 사용하여 여러 TTA 변환을 조합
transforms = tta.Compose(
[
tta.HorizontalFlip(), # 수평 반전 (좌우 뒤집기)
tta.Rotate90(angles=[0, 180]), # 90도 단위 회전 (0도와 180도로 설정)
tta.Scale(scales=[1, 2, 4]) # 크기 조정 (1배, 2배, 4배로 확대)
]
)
# 모델에 TTA Wrapper 적용
# SegmentationTTAWrapper를 사용하여 TTA 변환을 모델에 적용
tta_model = tta.SegmentationTTAWrapper(model, transforms)
# TTA 적용 후 예측 수행
# 각 TTA 케이스에 대해 모델 예측을 수행하고 결과를 결합하여 반환
masks = tta_model(images)
# merge_mode를 'mean'으로 설정하여 TTA 결합 방식을 평균으로 설정
# 여러 TTA 케이스의 예측 결과를 평균하여 결합
tta_model = tta.SegmentationTTAWrapper(model, transforms, merge_mode='mean')
Pseudo labeling, Crop Sliding window, object-dection Sliding window 등 다양한 기법들이 있다.
Ensemble 에 대해서는 여기까지 소개 하겠다.
이상입니다. 끝.
감사합니다.
'딥러닝 (Deep Learning) > [06] - 평가 및 결과 분석' 카테고리의 다른 글
| Object Detection 정의와 Evaluation metric (평가지표) (3) | 2024.10.02 |
|---|---|
| Class Activation Mapping (CAM)과 Grad-CAM (1) | 2024.08.29 |
| ZFNet 딥러닝 모델 시각화와 데이터 증강(Augumentation) 이해 (3) | 2024.08.29 |