1. TensorRT 란?
TensorRT는 NVIDIA가 개발한 고성능 딥러닝 추론 라이브러리로, 다양한 딥러닝 프레임워크에서 학습된 모델을 가져와 GPU에서 최적화된 엔진 형태로 변환하고 실행해준다. 내부적으로 딥러닝 추론 최적화 컴파일러와 런타임(runtime)으로 구성되며, 모델을 하드웨어에 맞게 최적 최적화하여 짧은 지연 시간과 높은 처리량의 추론을 가능하게 한다.
2. TensorRT 구조 (workflow)
TensorRT에서 모델 추론 파이프라인을 이해하기 위해 주요 구성 요소를 살펴보자.

TensorRT Workflow
- Training Framework
모델은 PyTorch, TensorFlow, Keras 등 다양한 프레임워크에서 학습된다. 학습된 모델을 TensorRT로 최적화하려면 일반적으로 ONNX (Open Neural Network Exchange) 형식으로 변환해야 한다. - NEURAL NETWORK
변환된 ONNX 모델은 TensorRT로 넘겨지며, 이때 두 가지 중요한 설정이 함께 제공된다.- Batch Size: 추론 시 입력할 데이터의 묶음 크기
- Precision: 추론 연산 정밀도 (FP32, FP16, INT8)
- Optimize using TensorRT
이 단계에서 TensorRT는 모델을 최적화한다. 대표적인 최적화 기법은 다음과 같다.- Layer Fusion (여러 연산 합치기)
- Kernel Auto-Tuning (하드웨어별 최적 커널 선택)
- Precision Calibration (FP16/INT8 변환 시 정밀도 유지)
- PLAN (Engine)
최적화된 모델은 .plan 또는 .engine 형식의 파일로 Serialize to Disk 된다.
이 엔진은 나중에 재사용이 가능하고, TensorRT 런타임에서 직접 로드하여 빠르게 추론할 수 있다. - Validate using TensorRT
최적화된 엔진을 로딩하여 실제 입력 데이터를 넣고 추론을 수행한다.
이 과정을 통해 최적화 전과 비교하여 성능 향상 여부, 정확도 유지 여부를 검증할 수 있다.
3. GPU 최적화 수행 방식
TensorRT는 엔진을 생성하는 빌드 단계에서 다양한 GPU 최적화 기법을 적용하여 모델을 고속화한다. 대표적인 최적화 방법으로 레이어 통합(layer fusion), 커널 자동 튜닝(kernel auto-tuning), 동적 텐서 메모리 관리(dynamic tensor memory), 그리고 연산 정밀도 감소 및 캘리브레이션(precision calibration) 등이 있다.
각각의 메커니즘을 하나씩 살펴보자.
1) 레이어 통합 (Layer fusion)
레이어 통합은 신경망의 여러 연산을 하나로 병합하여 실행 효율을 높이는 최적화이다.

위의 그림에서 맨 왼쪽은 최적화 전 Inception 모듈의 그래프로, conv + bias + ReLU와 같은 연산들이 개별 계층으로 나열되어 있다. 오른쪽은 TensorRT가 최적화한 후의 그래프로, 연속된 연산들이 하나의 커널로 합쳐진 3x3 또는 5x5 CBR 블록으로 변환된 것을 볼 수 있다.
이처럼 수직 방향으로 연산을 묶는 vertical fusion과, 병렬 분기 구조의 유사 연산을 결합하는 horizontal fusion을 통해 전체 레이어 수가 크게 감소한다. 실제로 TensorRT로 ResNet, Inception-v3 등의 모델을 최적화하면 그래프의 노드(레이어) 수가 원본 대비 수 배에서 수십 배까지 감소할 정도로 단순화된다.
TensorRT 빌더는 엔진 생성 시 합칠 수 있는 연산 패턴을 찾아내어 하나의 연산으로 치환한다. 예를 들어 합성곱 계층 뒤에 바로 ReLU 활성화 함수가 오는 패턴은 이를 하나의 합성곱 커널로 융합하여 실행하도록 최적화된다. 실제 내부 구현에서는 합성곱 연산 커널에 후속 ReLU 처리를 옵션으로 포함시켜, 별도 커널을 실행하지 않고도 합성곱 출력에 즉시 ReLU를 적용할 수 있게 된다. 이와 같이 통합 가능한 경우라면, TensorRT는 여러 레이어를 단일 커널로 합쳐 메모리 읽기/쓰기 횟수를 줄이고 연산 런치 오버헤드를 감소시킨다. 수평적 통합의 예로는 동일한 입력에 대해 서로 다른 가중치를 가진 여러 합성곱이 병렬로 적용된 경우(예: Inception 모듈의 1x1 conv 여러 개) 이를 하나의 커다란 연산으로 합치는 것이다. TensorRT는 이러한 패턴을 탐지하여 내부적으로 지원되는 경우 하나로 결합한다. 통합 결과로 GPU 상에서는 더 적은 수의 커널 호출로 동일한 작업을 수행하게 되어 레이턴시가 감소하고 메모리 대역폭 효율이 높아진다.
2) 커널 자동 튜닝 (Kernel Auto-Tuning)
딥러닝 연산(합성곱, 행렬곱 등)은 구현 방식이나 메모리 접근 패턴에 따라 여러 가지 커널(kernel) 옵션이 존재한다. TensorRT는 엔진 빌드 시 지원 가능한 모든 구현 전략(stactic)들을 시도하고 프로파일링하여 대상 하드웨어에서 가장 빠른 커널을 선택한다. 이를 커널 자동 튜닝 혹은 전략 선택 과정이라고 부른다.
예를 들어 합성곱의 경우 직접 im2col 후 매트릭스 곱을 할 수도 있고 FFT 기반으로 수행할 수도 있는데, TensorRT 빌더는 이러한 대안들을 실행해보며 걸리는 시간을 비교한 뒤 최적의 방법을 채택한다. 또한 하드웨어 아키텍처별로 최적 실행 경로가 다르기 때문에, 빌더는 엔진 생성 시 현재 GPU의 연산 능력에 맞춰 (예: Tensor Core 활용 가능 여부 등) 최적 파라미터를 자동 설정한다. 사용자가 별도로 지정하지 않으면, 빌더가 알아서 최적 배치 크기나 워크스페이스 크기를 고려해 엔진을 구성하며, 필요하다면 레이어별로 반정밀도(FP16)나 8비트 정수(INT8)로의 다운샘플링도 적용한다.
위의 말을 좀 더 쉽게 풀어보면,
딥러닝 모델을 GPU에서 빠르게 실행하려면, 같은 연산이라도 "어떻게 계산하느냐"에 따라 속도가 달라진다.
TensorRT는 딥러닝 모델을 최적화해서 빠르게 만들어주는 도구인데, 다음과 같은 과정을 거친다.
- 모델 안에 "합성곱(convolution)" 같은 연산이 있다면,
- 이 연산을 처리하는 방법은 여러 가지가 있어요 (A방법, B방법, C방법...).
- TensorRT는 각 방법을 실제로 다 실행해보고 어떤 방법이 제일 빠른지 확인해요.
- 그리고 가장 빠른 방법을 선택해서 최종 엔진을 만들어요.
이 과정을 "커널 자동 튜닝"이라고 부른다.

TensorRT의 튜닝 과정은 빌드 시간에 이루어지며, 이 때 다수의 후보 커널을 실행해보는 프로파일링 작업이 포함되므로 엔진 생성 속도가 느릴 수 있다. 그러나 이렇게 함으로써 런타임 시 최적의 커널만 사용하게 되어 추론 속도가 극대화된다. 일부 매우 특수한 최적화(예: 구조적 sparsity 활용 등)도 상황에 따라 적용되며, 이 역시 자동으로 가장 이득이 큰 경우에만 선택된다.
| 용어 | 설명 |
| 커널 | GPU에서 연산을 실행하는 작은 함수 또는 코드 조각이다. 예를 들어 "합성곱"을 계산하는 코드도 하나의 커널이다. |
| im2col | 합성곱을 더 빠르게 계산하기 위해 이미지를 펼쳐서(=flatten) 행렬 곱셈으로 바꾸는 기법 |
| FFT (Fast Fourier Transform) | 이미지나 데이터를 주파수로 바꿔서 연산을 더 빠르게 하려는 방법이다. 가끔 합성곱을 이걸로 처리하면 빠를 수 있다. |
| Tensor Core | NVIDIA GPU에 들어있는 고속 연산 유닛이다. FP16(반정밀도) 연산을 아주 빠르게 해준다. |
| FP16 / INT8 | FP32(기본값)보다 작게 표현하면 연산 속도가 빨라진다. 정확도가 약간 떨어질 수 있지만 속도가 크게 향상 됨. |
| 워크스페이스 크기 | 임시로 메모리를 사용하는 공간이다. 이 크기에 따라 빠르게 연산할 수 있는 방법이 달라지기도 하다. |
3) 동적 텐서 메모리 관리 (Dynamic Tensor Memory)
딥러닝 모델 실행 시 중간 텐서들이 다수 생성되며 메모리를 차지한다. TensorRT는 엔진 최적화 시 동적 텐서 메모리 관리를 적용하여, 각 텐서가 사용되는 기간에만 메모리를 할당하고 이후 바로 재활용할 수 있도록 한다. 즉, 한 연산의 출력이 다음 연산에 소비되고 나면 해당 메모리 공간을 다른 텐서에 재사용하여 전체 메모리 감소시킨다.
이러한 메모리 최적화는 GPU 메모리가 제한된 환경에서 특히 유용하며, 동일 자원으로 더 큰 배치나 더 큰 모델을 실행할 수 있게 해준다. TensorRT 엔진 빌더는 그래프 상의 텐서 생성-소멸 시점을 분석하여 메모리 "풀(pool)"을 효율적으로 운용한다. 이 과정 덕분에 불필요하게 메모리를 오래 점유하는 경우를 줄이고, GPU 메모리를 보다 효율적으로 활용한다. 결과적으로 메모리 대역폭 부담도 경감되어 약간의 성능 향상에도 기여한다.
(참고로 TensorRT는 여기에 더해 멀티 스트림 실행(multi-stream execution)도 지원하여, 여러 입력 스트림을 병렬 처리함으로써 GPU 활용도를 높일 수 있다.)
4) 정밀도 캘리브레이션 (FP32 → FP16/INT8)
TensorRT의 또 다른 핵심 최적화는 연산 정밀도 감소를 통한 속도 향상이다. 일반적으로 딥러닝 모델은 FP32(32-bit 부동소수)로 학습되지만, 추론 시에는 FP16(16-bit)이나 INT8(8-bit)과 같은 낮은 정밀도로 계산해도 충분한 경우가 많다. 낮은 비트로 연산하면 같은 연산이라도 처리 속도가 빨라지고 메모리 점유가 줄어드는 이점이 있다. TensorRT는 이러한 양자화(quantization)를 자동으로 적용하며, 크게 두 가지 방식이 있다.
- FP16 활용
대상 GPU가 FP16 빠른 경로(Tensor Core 등)를 지원한다면 엔진 빌드 시 FP16 모드를 활성화하여 많은 레이어를 FP16으로 실행한다. FP16은 FP32에 비해 표현 범위가 좁지만, 일반적으로 신경망의 가중치와 활성값은 어느 정도 노이즈에 내성이 있어 FP16로 변환해도 정확도 저하가 미미하다. TensorRT는 사용자가 FP16 모드를 켜두면 각 레이어별로 FP32 vs FP16 실행을 비교해가며 더 빠른 쪽으로 선택한다. 현재 GPU에서는 대체로 FP16 연산이 FP32보다 빠르므로, 특별한 이유가 없다면 FP16 모드를 켜고 엔진을 생성하는 것이 권장된다.
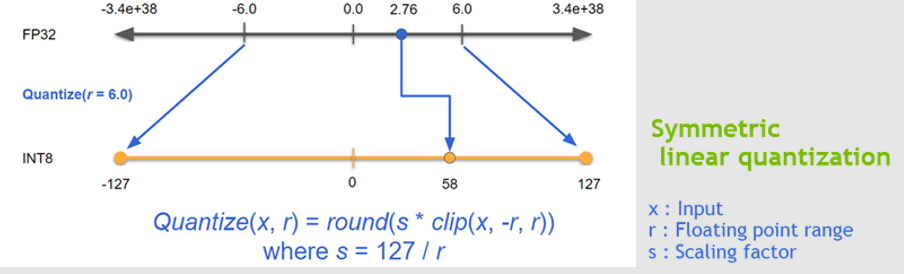
- INT8 양자화
8-bit 정수는 부동소수점에 비해 표현 범위가 극히 제한적이므로 부적절하게 양자화하면 모델 정확도가 크게 떨어질 수 있다. 따라서 TensorRT는 INT8 모드를 사용하려면 캘리브레이션(calibration) 과정을 거치도록 하고 있다. 캘리브레이션이란, 사용자가 제공하는 대표적인 입력 데이터셋을 통해 신경망 각 층의 출력 분포를 수집한 후, FP32 값들을 INT8로 맵핑하기 위한 스케일링 계수들을 결정하는 절차를 말한다. TensorRT는 기본적으로 KL-발산(Kullback–Leibler divergence)을 활용하여 FP32 분포와 INT8 분포 간 차이를 최소화하는 최적의 임계값(Threshold)을 찾는다. 이를 위해 수십~수백 개의 샘플을 네트워크에 통과시켜 각 레이어별 활성값 히스토그램을 모은 뒤, 적절한 양자화 범위를 계산한다. 이런 과정을 자동화해주는 TensorRT 제공 클래스가 IInt8Calibrator이며, 구현으로 엔트로피(minimum KL) 방식의 EntropyCalibrator2나 최솟값-최댓값 기반의 MinMaxCalibrator 등이 있다. 사용자는 보통 소량의 대표 입력(예: 수백 장의 이미지)을 준비하여 캘리브레이터에 공급하고 엔진을 빌드하게 된다. 캘리브레이션 완료 후 생성된 INT8 엔진은, 대부분의 연산을 INT8 정밀도로 수행하면서도 원본 FP32 모델에 근접한 정확도를 유지한다.
정밀도 캘리브레이션을 통해 TensorRT는 혼합 정밀도(mixed precision) 추론을 구현한다. 엔진 내 각 층은 FP32, FP16, INT8 중 가장 적합한 방식으로 실행될 수 있으며, 전체적으로 성능을 극대화하면서도 주어진 정확도 목표를 만족시키도록 자동 조율된다. 예를 들어 민감한 연산은 FP32로 남기고 나머지는 INT8로 처리하는 식이다. 이러한 기능 덕분에 사용자는 별도의 모델 수정 없이도 TensorRT 엔진 빌드 옵션만으로 손쉽게 속도-정확도 트레이드오프를 조절할 수 있다.
이상으로 TesnsorRT 개념 및 이해를 마치겠습니다.
추후 TensorRT 변환하여 추론까지 하는 코드 공유 하겠습니다.
감사합니다.
'딥러닝 (Deep Learning) > [04] - 학습 및 최적화' 카테고리의 다른 글
| OpenVino 란? (0) | 2025.04.02 |
|---|---|
| PyTorch(.pt) vs ONNX 무엇이 다르고, 왜 ONNX 추론이 더 빠를까? (2) | 2025.03.14 |
| [Optimizer] - 일반적으로 왜 Adam만 사용할까? [2] (2) | 2025.01.01 |
| [Optimizer] - 초기 optimizer 이해 [1] (3) | 2024.12.28 |
| Pseudo 라벨링(Pseudo Labeling)이란 무엇인가? (0) | 2024.11.24 |