Pytorch 모델을 훈련시킨 후 보통 .pt 확장자의 파일로 저장하며, 배포시에는 ONNX 포맷으로 내보내어(.onnx 파일) ONNX Runtime으로 추론하는 경우가 많습니다.
이번 글에서는 Pytorch의 .pt 파일과 ONNX 파일의
구조적 차이,
동적 그래프 vs. 정적 그래프 개념,
ONNX Runtime의 최적화 기법과 가속 엔진(TensorRT, OpenVINO, DirectML),
성능 비교까지 분석해보겠습니다.
1. PyTorch(.pt) 파일 vs ONNX 파일 구조
(1) Pytorch(.pt) 파일
Pytorch(.pt) 파일은 Pytorch 모델의 저장 형식으로, 내부 내용은 어떻게 저장하느냐에 따라 몇 가지 유형이 있습니다.
가장 흔한 방법은 모델의 state dict(가중치 딕셔너리)를 .pt(혹은 .pth)로 저장하는 것으로, 이 경우 파일에는 각 레이어의 가중치 텐서들이 Python pickle 직렬화 형태로 담깁니다
Pickle 직렬화 형태란 Python 객체를 pickle 모듈을 이용하여 바이너리 형식으로 저장한 데이터 형태를 의미
| 비교항목 | Pickle | JSON |
| 데이터 형식 | 바이너리 (.pkl) | 텍스트 (.json) |
| 사람이 읽을 수 있는가? | ❌ (읽기 어려움) | ✅ (읽기 쉬움) |
| Python 전용 데이터 지원 | ✅ (모든 Python 객체 지원) | ❌ (기본 데이터형만 지원) |
| 타 프로그래밍 언어 호환 | ❌ (Python 전용) | ✅ (언어 독립적) |
이렇게 저장된 pt 파일은 모델의 구조(연산 그래프) 정보는 포함하지 않고 학습된 가중치만 담고 있기 때문에, 다시 사용하려면 동일한 모델 클래스 정의가 있는 코드에서 state dict를 불러와 모델에 주입해야 합니다.
한편, torch.save(model, 'model.pt')처럼 모델 객체 자체를 저장할 수도 있는데, 이 경우에도 Python pickle로 저장되어 원본 클래스 정의가 있어야 로드할 수 있으며, 다른 환경이나 언어로 바로 활용하기 어렵습니다.
(2) ONNX 파일
ONNX(Open Neural Network Exchange) 파일은 딥러닝 모델을 저장하고 공유하는 표준 파일 형식입니다.
Pytorch, TensorFlow, Keras 등 다양한 딥러닝 프레임워크에서 학습한 모델을 같은 ONNX 형식으로 변환하여 저장하고, 다른 환경에서도 실행할 수 있도록 만들어졌습니다.
ONNX 파일의 특징
ONNX 파일은 내부적으로 프로토콜 버퍼(Protobuf)로 저장된 이진 파일입니다.
이 파일은 딥러닝 모델의 연산 그래프(Computation Graph)와 가중치(Weights)를 포함하고 있습니다.
즉, ONNX 파일 하나만 있으면 모델 구조(연산 방식)와 학습된 가중치를 함께 저장할 수 있기 때문에, 특정 프레임워크에 종속되지 않고 다른 환경에서도 동일한 모델을 실행할 수 있습니다.
ONNX 파일 내부 구조
ONNX 파일은 onnx.ModelProto라는 자료구조를 사용하여 저장됩니다.
이 안에는 모델을 실행하기 위한 여러 가지 중요한 정보가 포함됩니다.
✔ 연산 그래프(Computation Graph)
- 신경망의 각 연산(예: 합성곱, 활성화 함수, 행렬 곱셈 등)이 어떻게 연결되어 있는지를 나타냅니다.
- PyTorch나 TensorFlow의 연산 방식과 다를 수 있기 때문에, ONNX에서 지원하는 연산자(OpSet)로 변환됩니다.
✔ 노드(Node)와 연산자(OP, Operator)
- ONNX의 "노드(Node)"는 신경망의 각 레이어 또는 연산을 의미합니다.
- 예를 들어, ReLU 활성화 함수는 ONNX 내부적으로 "Relu"라는 연산자로 저장됩니다.
- 이를 통해 PyTorch, TensorFlow 등에서 사용된 연산을 ONNX에서도 동일하게 실행할 수 있습니다.
✔ 입력(Input)과 가중치(Initializer)
- 모델이 데이터를 받을 입력 형태를 정의합니다.
- 학습된 가중치(Weights)와 편향(Bias) 값도 함께 포함됩니다.
- 이를 통해 학습이 끝난 모델을 다시 훈련할 필요 없이 바로 실행할 수 있습니다.
2. PyTorch(.pt) vs ONNX 동작 방식 차이
Pytorch의 .pt 모델(특히 eager 모드에서의 모델)은 동적 그래프 방식으로 동작합니다. 즉, 매번 입력을 넣어 forward를 호출할 때 파이썬 코드를 따라 즉석에서 연산들이 실행되며, 필요하면 그때그때 그래프가 만들어졌다 소멸합니다. 이러한 Define-by-Run 방식은 유연성이 높고 디버깅이 쉬우며 Python 언어와 밀접하게 통합된 장점이 있지만, 추론 단계에서 매 iteration마다 불필요한 오버헤드가 발생할 수 있습니다.
비유: 레고 조립할 때 → 블록을 하나씩 끼우면서 "즉석에서 조립하며 실행"
(매번 조립할 때마다 새롭게 구조가 달라질 수 있음)
ONNX 모델은 정적 그래프 형태이므로, 한 번 정의된 계산 그래프를 그대로 재사용하면서 런타임 최적화된 C++ 커널들로 실행합니다. ONNX 모델을 로드한 후에는 Python 계층의 개입 없이 C/C++로 구현된 연산자들이 순서대로 실행되므로, PyTorch의 eager 모드처럼 매번 그래프를 생성/해체하는 비용이 없습니다. 또한 ONNX는 프레임워크에 독립적이므로, .pt와 달리 타 언어/환경(예: C++, Java, 웹 등)에서도 ONNX Runtime 등을 통해 그대로 모델을 사용할 수 있다는 이식성 장점도 있습니다.
비유: 레고 조립할 때 → 이미 완성된 모델을 복사해서 여러 번 사용
(매번 다시 조립할 필요 없이 빠르게 실행)
비교
| 비교 항목 | Pytorch | ONNX |
| 그래프 생성 방식 | 동적 그래프 (Define-by-Run) | 정적 그래프 (Predefined Graph) |
| 연산 실행 방식 | 매번 forward() 호출 시 즉석에서 실행 | 한 번 그래프 생성 후 재사용 |
| 디버깅 | ✅ 쉽고 직관적 (Python 코드 그대로 실행) | ❌ 어렵고 디버깅 불편 (고정된 그래프) |
| 최적화 | ❌ Python이 개입하여 오버헤드 발생 | ✅ C++ 기반 최적화 (빠름) |
| 이식성 | ❌ Python 환경 필요 (PyTorch 설치 필수) | ✅ 다양한 환경에서 사용 가능 (C++, Java, Web 등) |
| 추론 속도 | 상대적으로 느림 (매번 그래프 생성/삭제) | 빠름 (고정된 그래프 실행) |
| 사용 예시 | 연구, 실험, 프로토타이핑 | 실서비스 배포 (Inference 최적화) |
3. ONNX Runtime의 최적화 기법: 그래프 최적화 & 연산자 융합
ONNX 파일로 저장된 모델은 ONNX Runtime을 통해 실행됩니다. ONNX Runtime은 고성능 추론 엔진으로서, 모델을 로드할 때 다양한 "그래프 최적화(graph optimizations)"를 자동으로 적용합니다. 이는 ONNX Runtime의 핵심 강점 중 하나로, 기본적으로 모든 최적화가 디폴트 활성화되어 있으며 여러 단계(Level)로 나누어 진행됩니다
ONNX Runtime에서 그래프 최적화(graph optimization) 를 한다는 것은,
ONNX 모델의 연산 그래프(Computation Graph)를 더 빠르게 실행할 수 있도록 변형하는 과정을 의미합니다.
즉, 불필요한 연산을 제거하거나, 연산을 결합하여 실행 속도를 향상시키는 작업을 자동으로 수행하는 것입니다.
- 상수 폴딩(Constant Folding): 입력과 무관한 상수 노드들의 연산을 로드 시점에 미리 계산하여 그래프를 단순화합니다. 예를 들어, 어떤 레이어가 상수 텐서를 더하는 연산만 있다면, 그 결과를 미리 계산해 해당 노드를 제거함으로써 추론시 계산을 줄입니다.
- 불필요한 노드 제거: Identity처럼 입력 값을 그대로 통과시키기만 하는 연산자나, 쓰이지 않는 노드 등 중복되거나 의미 없는 노드들을 제거합니다. 이는 그래프를 간소화하여 추론시 연산 횟수를 줄입니다.
- 연산자 융합(Operator Fusion): 이것이 성능 최적화에 특히 중요한데, 여러 연산을 하나로 결합하여 실행하는 기법입니다. 예를 들어 Conv + Add 패턴이 발견되면 Add를 Conv 연산의 bias로 통합하거나, Conv + BatchNormalization 패턴을 하나의 Conv 노드로 합치는 등 일반적인 레이어 조합을 단일 커널로 융합합니다. ONNX Runtime는 이러한 시맨틱을 보존하는 노드 융합을 다수 지원하여, 그래프 실행 효율을 높입니다 (Conv+Add Fusion, Conv+Mul Fusion, Conv+BatchNorm Fusion 등 그 외에도 LSTM Fusion 등 복잡한 패턴들도 최적화 대상일 수 있습니다)
- 레이아웃 최적화(Layout Optimization): 필요에 따라 텐서의 메모리 레이아웃(NCHW ↔ NHWC 등)을 변경하여 특정 하드웨어에서 효율을 높일 수도 있습니다. 예를 들어 GPU에서는 연산에 따라 채널-last(NHWC) 형식이 유리할 수 있는데, 런타임이 이런 결정을 해줄 수 있습니다.
ONNX Runtime의 아키텍처적 목표는, 제공된 ONNX 모델을 주어진 하드웨어에서 가능한 한 빠르게 실행하는 것입니다. 이를 위해 위와 같은 그래프 최적화뿐 아니라, 하드웨어별 최적화된 커널을 선택하고 스레드/메모리 관리도 조정합니다. MSRA 팀의 발표에 따르면, ONNX Runtime은 다양한 하드웨어에서 병렬 실행 및 동적 배칭 등을 통해 성능을 극대화하도록 설계되었습니다. 이러한 자동 최적화 덕분에 별다른 수작업 튜닝 없이도 ONNX 모델은 기본 PyTorch 추론 대비 성능 향상을 얻는 경우가 많습니다.
4. ONNX 모델 가속: TensorRT, OpenVINO을 활용한 최적화 방법
ONNX Runtime은 다양한 하드웨어에서 딥러닝 모델을 빠르게 실행할 수 있도록 최적화하는 엔진입니다.
ONNX 모델을 실행할 때, 단순히 CPU나 GPU만 사용하는 것이 아니라, 특정 하드웨어에 최적화된 실행 방식(Execution Provider, EP)을 적용하면 더욱 빠르게 추론할 수 있습니다.
ONNX Runtime에서 가장 대표적인 가속 기술로는 TensorRT(NVIDIA) 와 OpenVINO(Intel) 가 있습니다.
각각 NVIDIA GPU 와 Intel CPU/GPU 환경에서 최적의 속도를 제공하는 역할을 합니다.
(1) ONNX Runtime의 가속 개념: Execution Provider (EP)
ONNX Runtime은 자체적으로 모든 연산을 수행하지 않습니다.
대신, 각 하드웨어에 최적화된 실행 공급자(Execution Provider, EP)를 통해 연산을 위임합니다.
✔ Execution Provider(EP)란?
- ONNX Runtime이 사용하는 하드웨어 최적화된 연산 엔진입니다.
- CPU, GPU, TPU 등 다양한 하드웨어에 맞는 최적화된 연산 방식을 적용합니다.
- 사용자는 적절한 EP를 선택하는 것만으로 속도를 대폭 향상시킬 수 있습니다.
✔ ONNX Runtime의 기본적인 EP 종류
- CPU EP: 기본적으로 모든 CPU에서 실행 가능 (속도는 느린 편)
- CUDA EP: NVIDIA GPU에서 실행 가능 (일반적인 GPU 가속)
- TensorRT EP: NVIDIA GPU에서 더욱 빠르게 실행 (최적화된 추론)
- OpenVINO EP: Intel CPU/GPU에서 최적화된 실행 제공
(2) TensorRT EP: NVIDIA GPU에서 초고속 추론
TensorRT는 NVIDIA에서 제공하는 고성능 딥러닝 추론 엔진입니다.
ONNX Runtime과 결합하면 일반적인 GPU 실행보다 훨씬 빠르게 모델을 실행할 수 있습니다.
✔ TensorRT의 주요 기능
- FP16/INT8 저정밀 연산: 숫자의 표현 범위를 줄여 속도를 높이고 메모리 사용을 최적화
- 연산 병합(Fusion): 여러 개의 연산을 하나로 합쳐 실행 속도를 증가
- 텐서 메모리 최적화: GPU 메모리를 더 효율적으로 사용
✔ TensorRT가 유용한 모델 유형
- CNN 기반 모델 (예: ResNet, YOLO)
- Transformer 기반 모델 (예: BERT, GPT)
✔ TensorRT 사용 시 이점
- 일반적인 CUDA 실행보다 속도가 더 빠름
- NVIDIA GPU에서 연산을 극대화하여 추론 지연시간(Latency)을 줄임
import onnxruntime as ort
# TensorRT를 지원하는 Execution Provider 사용
session = ort.InferenceSession("model.onnx", providers=["TensorrtExecutionProvider"])
NVIDIA GPU가 필요하며, TensorRT 라이브러리가 설치되어 있어야 하며, 모든 연산이 TensorRT에서 지원되는 것은 아니므로, 지원되지 않는 연산은 기본 EP로 실행됩니다.
(3) OpenVINO EP: Intel CPU/GPU에서 최적화된 실행
OpenVINO는 Intel이 제공하는 딥러닝 모델 가속화 엔진입니다.
ONNX Runtime에서 OpenVINO를 사용하면 Intel CPU 및 내장 GPU에서 실행 속도를 극대화할 수 있습니다.
✔ OpenVINO의 주요 기능
- Intel CPU의 벡터 연산 최적화 (SSE, AVX, VNNI)
- GPU의 저정밀 연산(FP16) 지원
- VPU(NCS2)에서 실행 가능 (엣지 AI 가속)
✔ OpenVINO 사용 시 이점
- Intel CPU에서 기본 CPU 실행보다 훨씬 빠른 속도로 모델을 실행 가능
- Intel 내장 GPU에서도 가속 가능하여 GPU 비용 없이 최적화된 성능 제공
import onnxruntime as ort
# OpenVINO Execution Provider 사용
session = ort.InferenceSession("model.onnx", providers=["OpenVINOExecutionProvider"])
이렇게 실행하면 OpenVINO를 활용하여 Intel CPU에서 더욱 빠르게 모델을 실행할 수 있습니다.
✔ OpenVINO EP의 특징
- Intel CPU/GPU/VPU 하드웨어에서 실행 가능
- OpenVINO 라이브러리가 설치되어 있어야 함
(4) ONNX Runtime의 "하이브리드 실행" 기능
ONNX Runtime은 여러 개의 Execution Provider를 혼합하여 사용할 수도 있습니다.
예를 들어, 일부 연산은 CPU에서 실행하고, 일부 연산은 GPU에서 실행하는 방식입니다.
import onnxruntime as ort
# CPU와 TensorRT를 혼합하여 실행
session = ort.InferenceSession("model.onnx", providers=["TensorrtExecutionProvider", "CPUExecutionProvider"])
이렇게 설정하면 지원되는 연산은 TensorRT에서 실행하고, 나머지는 CPU에서 처리하게 됩니다.
(5) 정리
ONNX Runtime을 사용하면 딥러닝 모델의 실행 속도를 최적화할 수 있습니다.
특히 TensorRT와 OpenVINO 같은 가속 백엔드를 활용하면 하드웨어 성능을 극대화하여 추론 속도를 높일 수 있습니다.
| 가속 방식 | 지원 하드웨어 | 최적화 내용 | 장점 |
| TensorRT EP | NVIDIA GPU | FP16/INT8 최적화, 연산 병합 | CUDA보다 더 빠른 추론 |
| OpenVINO EP | Intel CPU/GPU | 벡터 연산 최적화, 저정밀 연산 | Intel 하드웨어에서 고속 실행 |
| CPU EP | 모든 CPU | 기본 실행 | 가장 일반적이지만 속도는 느림 |
| Hybrid EP | CPU + GPU | 일부 연산은 GPU, 일부는 CPU에서 실행 | 다양한 환경에서 성능 극대화 |
- ONNX Runtime은 딥러닝 모델을 실행할 때, 다양한 하드웨어 가속을 활용할 수 있도록 최적화된 엔진입니다.
- TensorRT를 사용하면 NVIDIA GPU에서 초고속으로 모델을 실행할 수 있으며, CNN, Transformer 모델에서 큰 성능 향상이 가능합니다.
- OpenVINO를 사용하면 Intel CPU/GPU에서 최적화된 추론을 수행할 수 있으며, 서버 및 엣지 AI 환경에서 유용합니다.
ONNX Runtime의 강력한 가속 기능을 활용하면 같은 하드웨어에서도 더 빠른 속도로 모델을 실행할 수 있으므로, 최적화가 중요한 딥러닝 프로젝트에서 필수적으로 고려해야 합니다.
5. ONNX Runtime의 내부 아키텍처 및 실행 과정
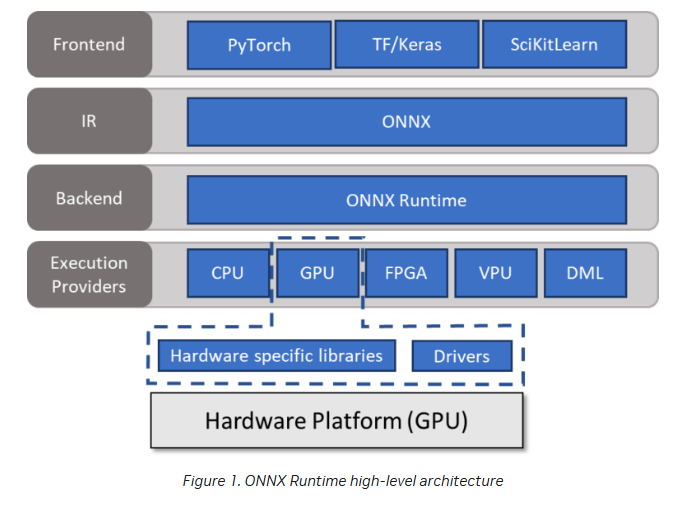
(1) ONNX Runtime의 전체 구조
① Frontend (프론트엔드)
✔ 딥러닝 모델을 만드는 단계
✔ PyTorch, TensorFlow/Keras, SciKit-Learn 같은 프레임워크에서 학습한 모델을 ONNX 형식으로 변환합니다.
② IR (Intermediate Representation, 중간 표현)
✔ 변환된 모델은 ONNX 포맷(ONNX IR) 으로 저장됩니다.
✔ ONNX IR은 모델의 구조와 연산을 설명하는 프레임워크 독립적인 형식입니다.
③ Backend (백엔드)
✔ ONNX Runtime이 모델을 실행할 준비를 하는 단계입니다.
✔ 연산을 어떤 하드웨어에서, 어떤 방식으로 실행할지 스케줄링합니다.
④ Execution Providers (실행 공급자, EP)
✔ 실제 연산이 실행되는 단계입니다.
✔ CPU, GPU, FPGA, VPU 등 다양한 하드웨어 가속기에서 실행할 수 있도록 지원합니다.
(2) Execution Providers (EP)의 역할
ONNX Runtime에서 모델이 실행되는 방식은 Execution Provider(EP)에 의해 결정됩니다.
EP는 특정 하드웨어에서 최적의 성능을 내도록 도와주는 실행 엔진입니다.
✅ 주요 Execution Providers
| EP 종류 | 설명 |
| CPU EP | 일반적인 CPU에서 실행 (속도는 가장 느림) |
| GPU EP (CUDA) | NVIDIA GPU에서 실행 (CUDA 가속) |
| TensorRT EP | NVIDIA TensorRT를 사용하여 최적화된 GPU 실행 |
| OpenVINO EP | Intel CPU/GPU에서 최적화된 실행 |
| FPGA EP | FPGA(프로그램 가능한 반도체)에서 실행 |
| VPU EP | 엣지 AI 가속기(Vision Processing Unit)에서 실행 |
| DirectML EP | Windows에서 GPU 가속을 활용 (DML API 사용) |
CPU와 GPU 외에도 전용 AI 가속기(FPGA, VPU)를 활용하여 최적화된 연산 실행이 가능합니다.
TensorRT, OpenVINO 같은 EP를 사용하면 같은 하드웨어에서도 더 빠르게 실행할 수 있습니다.
(3) ONNX Runtime 실행 과정
ONNX Runtime이 어떻게 모델을 실행하는지 간단하게 정리하면 다음과 같습니다.
1. 딥러닝 모델을 학습한 후, ONNX 형식으로 변환
- PyTorch 또는 TensorFlow에서 .onnx 파일로 변환
2. ONNX Runtime이 모델을 불러와 실행 계획을 수립
- 모델을 분석하고, 연산을 최적화한 후 Execution Provider(EP) 를 선택
3. 선택된 EP를 통해 최적의 하드웨어에서 실행
- CPU, GPU, TensorRT, OpenVINO 등 사용자가 지정한 하드웨어에서 실행
4. 출력 결과 반환
- ONNX Runtime은 최적화된 연산을 수행한 후 최종 결과를 반환
ONNX Runtime을 사용하면 PyTorch, TensorFlow에서 만든 모델을 다양한 하드웨어에서 최적화된 속도로 실행할 수 있습니다.
다음에는 예제 코드로 한번 더 이해해보겠습니다.
감사합니다.
'딥러닝 (Deep Learning) > [04] - 학습 및 최적화' 카테고리의 다른 글
| OpenVino 란? (0) | 2025.04.02 |
|---|---|
| TensorRT 개념 및 이해 (1) | 2025.03.27 |
| [Optimizer] - 일반적으로 왜 Adam만 사용할까? [2] (2) | 2025.01.01 |
| [Optimizer] - 초기 optimizer 이해 [1] (3) | 2024.12.28 |
| Pseudo 라벨링(Pseudo Labeling)이란 무엇인가? (0) | 2024.11.24 |