1. SVM 이란??
SVM, 즉 Support Vector Machine은 지도 학습(Supervised Learning)의 한 종류로,
주어진 데이터를 기반으로 새로운 데이터를 분류하는 데 사용되는 강력한 알고리즘입니다.
이 모델은 기본적으로 데이터를 분류할 수 있는 최적의 경계(또는 선)를 찾는 일을 합니다.
2. SVM의 기본 아이디어는 최적의 경계를 찾는 것!
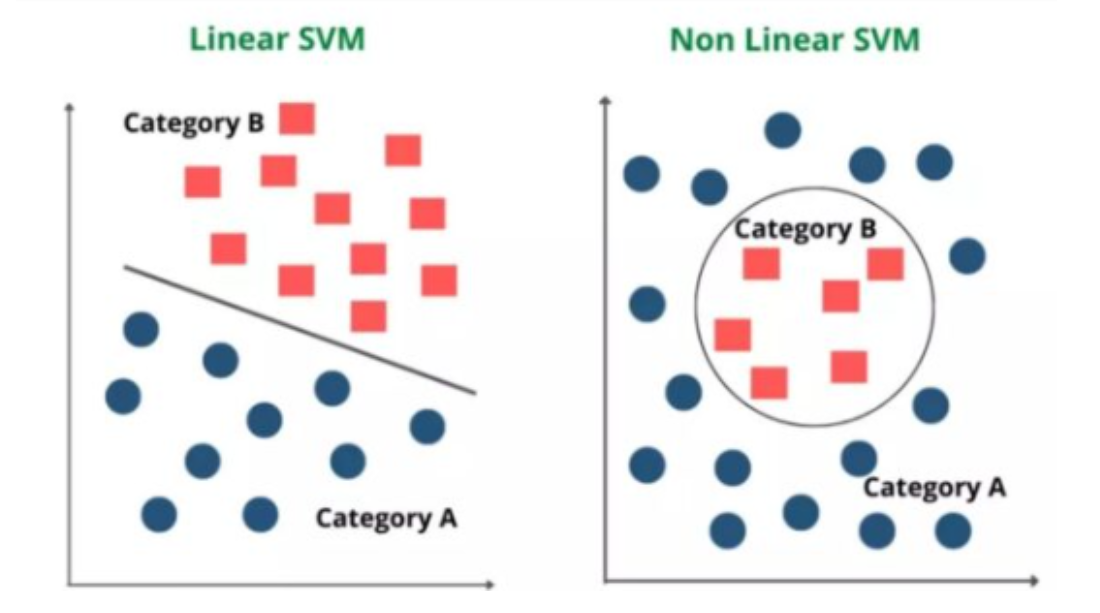
SVM은 두 클래스 사이의 Decision Boundary(결정 경계)를 찾습니다.
이 경계는 데이터를 가장 잘 분리할 수 있는 선을 의미합니다.
예를 들어,
키와 몸무게라는 두 가지 특징을 데이터를 이용해 사람들을 "운동 선수"와 "비운동 선수"로 분류하려고 합니다.
각 사람의 키와 몸무게는 좌표 평면에 점으로 나타낼 수 있습니다. SVM은 이 점들을 구분할 수 있는 최적의 선을 찾는것!
3. Support Vectors 와 Margin
SVM에서 가장 중요한 요소는 바로 Support Vectors 입니다.
Support Vectors 는 결정 경계에 가장 가까운 데이터 포인트들로,
이 포인트들이 결정 경계를 형성하는 데 핵심적인 역할을 합니다.
- 마진(Margin)은 결정 경계와 가장 가까운 Support Vectors 사이의 거리입니다.
SVM은 이 마진을 최대화하려고 하는데, 이는 마치 두 무리가 최대한 떨어져 있도록 선을 긋는 것과 같습니다.
이렇게 하면 새로운 데이터가 주어졌을 때, 그 데이터가 어느 쪽에 속할 가능성이 더 높은지 쉽게 판단할 수 있습니다.
SVM의 확장: 비선형 데이터의 처리

현실 세계의 데이터가 모두 선형으로 나눌 수 있는 것은 아니죠.
예를 들어, 동그라미 모양으로 분포된 데이터를 생각해 보세요. 이 경우, 직선으로는 두 클래스를 나눌 수 없습니다.
이 문제를 해결하기 위해 SVM은 커널 트릭(Kernel Trick)이라는 마법을 사용합니다.
커널 트릭을 사용하면 데이터를 더 높은 차원으로 변환하여, 그 차원에서 데이터를 선형적으로 나눌 수 있게 됩니다.
이렇게 하면, 원래는 복잡하게 얽혀 있던 데이터도 SVM에 의해 깔끔하게 분류될 수 있습니다.
왜 SVM이 중요 할까?
- 높은 성능: SVM은 특히 고차원 데이터에서 좋은 효과적
- 유연성: 다양한 커널 함수를 사용하여 비선형 문제도 해결
- 견고성: 과적합(Overfitting)을 방지하는 데 강력한 도구
'딥러닝 (Deep Learning) > [03] - 모델' 카테고리의 다른 글
| DeepLab v1 아키텍쳐 분석 (1) | 2024.11.20 |
|---|---|
| SegNet의 아키텍처 (3) | 2024.11.18 |
| Bottom-up Region Proposals 이란? [R-CNN] (4) | 2024.09.03 |
| Seq2Seq: Sequence-to-Sequence 모델 (0) | 2024.08.18 |
| LSTM(Long Short-Term Memory Networks) (0) | 2024.08.18 |