1. MMSegmentation이란?
MMDetection과 MMSegmentation은 모두 컴퓨터 비전 분야에서 널리 사용되는 오픈소스 라이브러리이다. 특히, MMSegmentation은 주로 이미지 세그멘테이션 작업에 특화된 프레임워크로, 다양한 세그멘테이션 모델과 학습 방식을 지원한다.
MMSegmentation은 OpenMMLab이라는 오픈소스 프로젝트의 일환으로 개발된 이미지 세그멘테이션을 위한 라이브러리이다. 이 프레임워크는 다양한 종류의 세그멘테이션 모델을 쉽게 구축하고 학습할 수 있도록 설계되어 있다. 대표적인 세그멘테이션 모델인 U-Net, DeepLab 시리즈, FCN(Fully Convolutional Network) 등을 지원하며, 최신 연구 결과와 알고리즘도 빠르게 반영하고 있다.
또한, 공식 주소에 상세한 내용 및 사용방법이 있으니 참고하자.
mmsegmentation/docs/en/get_started.md at main · open-mmlab/mmsegmentation
OpenMMLab Semantic Segmentation Toolbox and Benchmark. - open-mmlab/mmsegmentation
github.com
2. MMsegmentation 설치방법
1. 기본 패키지 설치
먼저, MMSegmentation에 필요한 기본 패키지들을 설치해 주어야 한다. VSCode의 터미널을 열고 아래 명령어를 순서대로 입력한다. 아래 명령어는 OpenMIM, MMEngine, 그리고 MMCV라는 필수 패키지를 설치하는 명령어이다.
pip install -U openmim
mim install mmengine
mim install "mmcv>=2.0.0"
2. Git을 통해 MMSegmentation 설치
다음으로 GitHub에서 MMSegmentation의 레파지토리를 클론하고 설치하는 과정이다. 아래 명령어를 사용하여 MMSegmentation의 코드를 다운로드한다
git clone -b main https://github.com/open-mmlab/mmsegmentation.git
cd mmsegmentation
pip install -v -e .
위 명령어를 실행하면, MMSegmentation의 소스 코드를 로컬 환경으로 가져온 후, 해당 폴더로 이동하여 필요한 부분을 설치하게 된다. pip install -v -e . 명령어는 개발 모드로 설치하기 위해 사용되며, 이렇게 하면 로컬에서 수정된 내용이 즉시 반영되어 사용할 수 있게 된다.
아래 그림 처럼 clone 하면 볼 수 있다.
3. MMsegmentation custom train 방법
1. PASCAL VOC 2012 데이터셋의 구성
PASCAL VOC 2012는 컴퓨터 비전 연구에서 널리 사용되는 데이터셋이다. 이 데이터셋은 주로 객체 검출(Object Detection), 이미지 분할(Semantic Segmentation), 그리고 이미지 분류(Classification) 등의 연구를 위해 활용된다. VOC 2012 데이터셋에는 총 21개의 클래스가 포함되어 있다. 이 클래스들은 다음과 같다.
The PASCAL Visual Object Classes Challenge 2012 (VOC2012)
2006 10 classes: bicycle, bus, car, cat, cow, dog, horse, motorbike, person, sheep. Train/validation/test: 2618 images containing 4754 annotated objects. Images from flickr and from Microsoft Research Cambridge (MSRC) dataset The MSRC images were easier th
host.robots.ox.ac.uk
- 배경 (Background): 기본적으로 모든 이미지에서 객체가 아닌 부분은 배경
- 사람 (Person):
- 동물 클래스:
- 새 (Bird)
- 고양이 (Cat)
- 소 (Cow)
- 개 (Dog)
- 말 (Horse)
- 양 (Sheep)
- 탈것 클래스:
- 비행기 (Aeroplane)
- 자전거 (Bicycle)
- 보트 (Boat)
- 버스 (Bus)
- 자동차 (Car)
- 오토바이 (Motorbike)
- 기차 (Train)
- 가구 및 일상 용품 클래스:
- 병 (Bottle)
- 의자 (Chair)
- 식탁 (Dining Table)
- 화분 (Potted Plant)
- 소파 (Sofa)
- TV 모니터 (TV Monitor)

위의 링크에서 PASCAL VOC 데이터셋을 다운로드 받을 수 있다.
다운로드 후, 아래 처럼 폴더가 구성되어 있다.

- Annotations
이 폴더에는 각 이미지에 대한 어노테이션 파일이 저장되어 있다. 어노테이션 파일은 XML 형식으로 되어 있으며, 객체의 위치와 클래스 정보를 담고 있다. 이 정보를 통해 객체 검출 모델이 이미지를 학습할 수 있다. - ImageSets
ImageSets 폴더는 훈련, 검증, 테스트 세트에 사용될 이미지의 리스트 파일들을 포함하고 있다. 이 파일들은 이미지 이름으로 구성된 텍스트 파일이며, 각 세트를 나누는 역할을 한다. ImageSets/Segmentation 폴더에는 세그멘테이션용 데이터셋 분할 목록이 들어 있다. - JPEGImages
JPEGImages 폴더에는 데이터셋에서 사용하는 원본 이미지 파일들이 저장되어 있다. 이미지는 보통 JPEG 형식으로 되어 있으며, 이 이미지들은 객체 검출과 분할 모델을 학습하는 데 사용된다. - SegmentationClass
이 폴더에는 세그멘테이션 클래스 라벨 이미지가 저장되어 있다. 각 이미지에 대해 픽셀 단위로 클래스가 할당된 라벨 이미지가 있으며, 이는 세그멘테이션 모델이 특정 객체의 경계를 학습하도록 도와준다. 라벨 이미지의 각 색상 값은 특정 객체 클래스에 대응된다. - SegmentationObject
SegmentationObject 폴더는 각 객체의 인스턴스별 세그멘테이션 정보를 포함하고 있다. 이는 이미지 내의 여러 객체를 개별적으로 구분할 수 있도록 해준다. 인스턴스 세그멘테이션을 위해 각 객체를 다른 색상으로 구분하는 라벨 이미지들이 저장되어 있다.
2. PASCAL 데이터로 FCN 모델로 학습 방법
MMSegmentation은 다양한 방법으로 커스텀 트레이닝을 진행할 수 있지만, 여기서는 별도의 트레인 파일을 생성하여 학습하는 방법을 소개하고자 한다. 프레임워크의 구조를 이해하는 것은 매우 중요하지만, 우선 실제 학습이 진행되는 것을 보고 구조를 파악하는 것이 이해하기 쉽다고 생각한다. 따라서, 일단 실행해 보고 구조를 파악한 뒤에 각자의 상황에 맞게 커스터마이징하기를 추천한다.
Step 1: 새로운 Train 파일 생성
우선 mmsegmentation 폴더에 train_fcn.py 파일을 생성하자. 이 파일에서 커스텀 학습을 진행할 것이다. 이 과정을 통해 기본 설정을 가져오고 이를 수정하여 우리가 원하는 방식으로 모델을 학습할 수 있게 된다.
Step 2: 기본 설정 파일 작성
이제 train_fcn.py 파일에 아래와 같은 코드를 작성하자.
_base_ = [
'configs/_base_/models/fcn_r50-d8.py', # 사용할 모델 설정 파일
'configs/_base_/datasets/pascal_voc12.py', # 데이터셋 설정
'configs/_base_/default_runtime.py',
'configs/_base_/schedules/schedule_20k.py'
]
위의 코드를 보면 model, datasets, default_runtime, schedules 가 기본적으로 작성되어 있는것을 불러오는 코드다.
우리는 custom 을 해야하기 때문에 해당하는 경로에 들어가서 코드를 확인 후 바꿔주면 된다.
Step 3: 기본 설정 수정하기
우리는 모델을 자신에게 맞게 커스터마이징해야 하기 때문에, 기본 설정 파일을 확인하고 필요한 부분을 수정해야 한다. 기본 설정 파일들은 MMSegmentation 폴더 내의 각 경로에 위치하고 있다. 따라서 해당 경로에 들어가서 직접 내용을 확인하고, 필요한 부분을 수정하면 된다.
fcn_r50_d8.py - 모델 설정 파일 수정
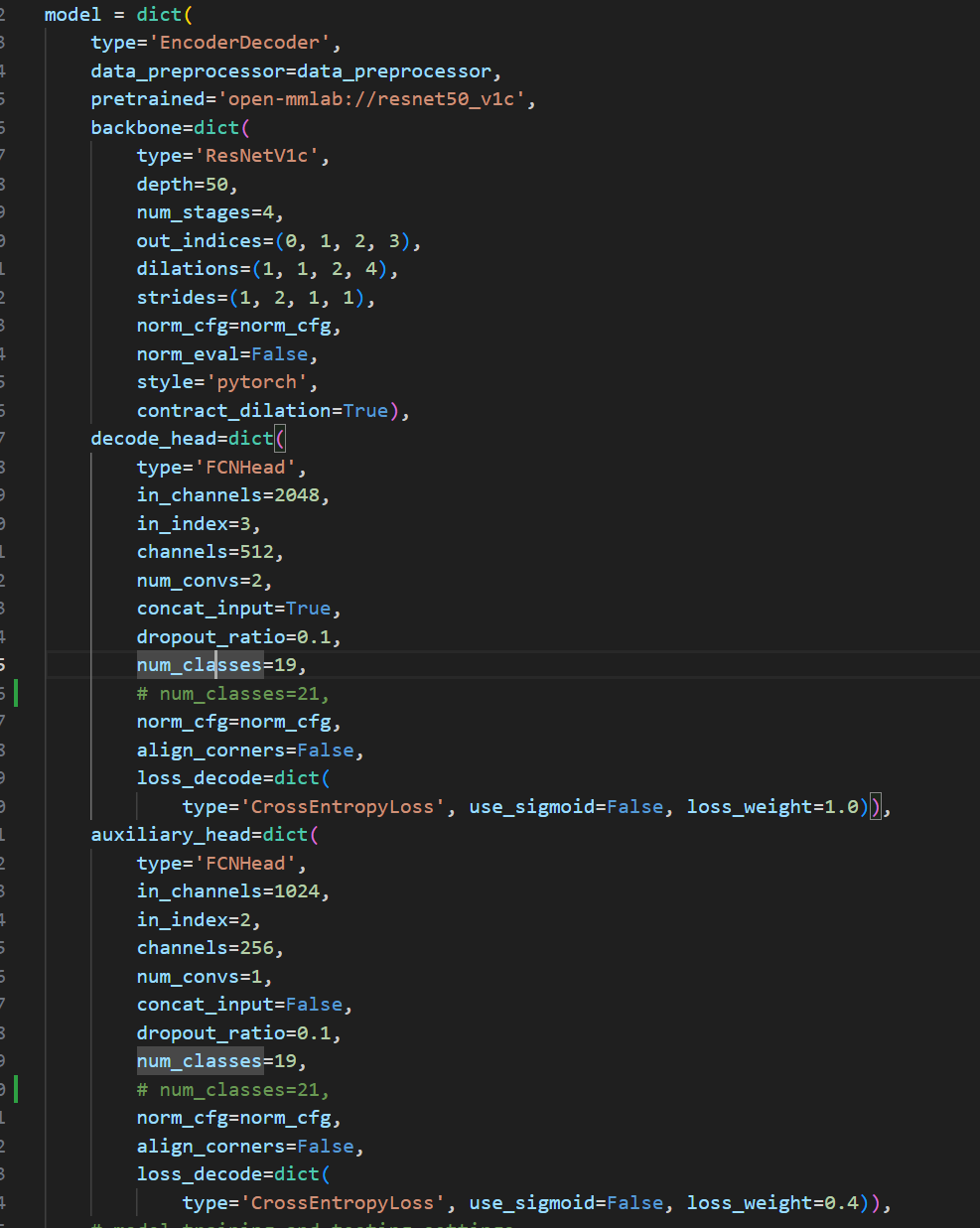
모델 설정 파일에서 우리가 바꿔야 할 부분은 num_classes이다. 기본값으로 설정된 num_classes를 우리의 custom 데이터에 맞게 변경해야 한다. 모델 구조의 변형이 필요하다면 파라미터를 추가로 작성하여 변경할 수 있다. 아래 코드를 train_fcn.py 파일에 추가하여 파라미터 값을 변경해 보자.
model = dict(
decode_head=dict(
num_classes=21, # num_classes
),
auxiliary_head=dict(
num_classes=21,
)
)
pascal_voc12.py - 데이터셋 설정 파일 수정
데이터셋 설정 파일에는 augmentation, data 경로, 정규화 등이 작성되어 있다. 우리는 custom 데이터를 사용하기 때문에 경로 부분을 설정하고, 나머지 부분은 기본 설정을 사용할 수 있다. 물론 변경하고 싶다면 파라미터 값을 수정하면 된다. 아래 코드를 train_fcn.py 파일에 추가하자.
# 데이터셋의 루트 경로
data_root = './VOC2012' # 데이터 경로
# 데이터 설정 덮어쓰기
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(
data_root=data_root,
data_prefix=dict(
img_path='JPEGImages', # 이미지 경로
seg_map_path='SegmentationClass' # 세그멘테이션 어노테이션 경로
),
ann_file='ImageSets/Segmentation/train.txt', # train 리스트 파일
),
val=dict(
data_root=data_root,
data_prefix=dict(
img_path='JPEGImages',
seg_map_path='SegmentationClass'
),
ann_file='ImageSets/Segmentation/val.txt', # val 리스트 파일
),
test=dict(
data_root=data_root,
data_prefix=dict(
img_path='JPEGImages',
seg_map_path='SegmentationClass'
),
ann_file='ImageSets/Segmentation/val.txt', # test 리스트 파일
)
)
train_dataloader = dict(
batch_size=4,
num_workers=4,
dataset=data['train'],
sampler=dict(type='DefaultSampler', shuffle=True),
persistent_workers=True,
)
default_runtime.py -기본 런타임 설정 파일 수정
default_scope = 'mmseg'
env_cfg = dict(
cudnn_benchmark=True,
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
dist_cfg=dict(backend='nccl'),
)
vis_backends = [dict(type='LocalVisBackend')]
visualizer = dict(
type='SegLocalVisualizer', vis_backends=vis_backends, name='visualizer')
log_processor = dict(by_epoch=False)
log_level = 'INFO'
load_from = None
resume = False
tta_model = dict(type='SegTTAModel')
기본 런타임 설정 파일에는 MMSegmentation 환경에서 모델 학습과 테스트를 효율적으로 수행하기 위한 다양한 옵션들이 정의되어 있다. 이를 통해 학습 시의 최적화, 분산 학습, 시각화, 로깅, 모델 불러오기, TTA 등을 관리할 수 있다. 기본 설정 파일에서 필요한 부분을 수정해 보자.
schedule_20k.py - 학습 스케줄 설정 파일 수정
기본 학습 스케줄 파일에서는 학습 반복 수(iterations), 학습률, 학습 전략 등이 정의되어 있다. 필요에 따라 이 설정들을 수정해 주면 된다. 예를 들어, 학습 반복 수를 늘리거나 줄이거나, 학습률을 변경하여 더 좋은 성능을 얻을 수 있다.

optimzier 코드 변경부분을 추가하여 학습해보자.
optimizer = dict(type='AdamW', lr=0.0001, weight_decay=0.01)
Step 4: 학습
아래 코드는 train_fcn.py 모든 코드이며, 코드를 실행해서 학습해보자
_base_ = [
'configs/_base_/models/fcn_r50-d8.py', # 사용할 모델 설정 파일
'configs/_base_/datasets/pascal_voc12.py', # 데이터셋 설정
'configs/_base_/default_runtime.py',
'configs/_base_/schedules/schedule_20k.py'
]
model = dict(
decode_head=dict(
num_classes=21, # num_classes
),
auxiliary_head=dict(
num_classes=21,
)
)
# 데이터셋의 루트 경로
data_root = './VOC2012' # 데이터 경로
# 데이터 설정 덮어쓰기
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(
data_root=data_root,
data_prefix=dict(
img_path='JPEGImages', # 이미지 경로
seg_map_path='SegmentationClass' # 세그멘테이션 어노테이션 경로
),
ann_file='ImageSets/Segmentation/train.txt', # train 리스트 파일
),
val=dict(
data_root=data_root,
data_prefix=dict(
img_path='JPEGImages',
seg_map_path='SegmentationClass'
),
ann_file='ImageSets/Segmentation/val.txt', # val 리스트 파일
),
test=dict(
data_root=data_root,
data_prefix=dict(
img_path='JPEGImages',
seg_map_path='SegmentationClass'
),
ann_file='ImageSets/Segmentation/val.txt', # test 리스트 파일
)
)
train_dataloader = dict(
batch_size=4,
num_workers=4,
dataset=data['train'],
sampler=dict(type='DefaultSampler', shuffle=True),
persistent_workers=True,
)
# 학습 스케줄 및 optimizer 설정
optimizer = dict(type='AdamW', lr=0.0001, weight_decay=0.01)
# lr_config = dict(policy='poly', power=0.9, min_lr=1e-5, by_epoch=False)
# runner = dict(type='IterBasedRunner', max_iters=20000)
# checkpoint_config = dict(by_epoch=False, interval=2000)
# evaluation = dict(interval=2000, metric='mIoU')
mmsegmentation 폴더에서 아래 명령어로 실행하자.
python tools/train.py train_fcn.py
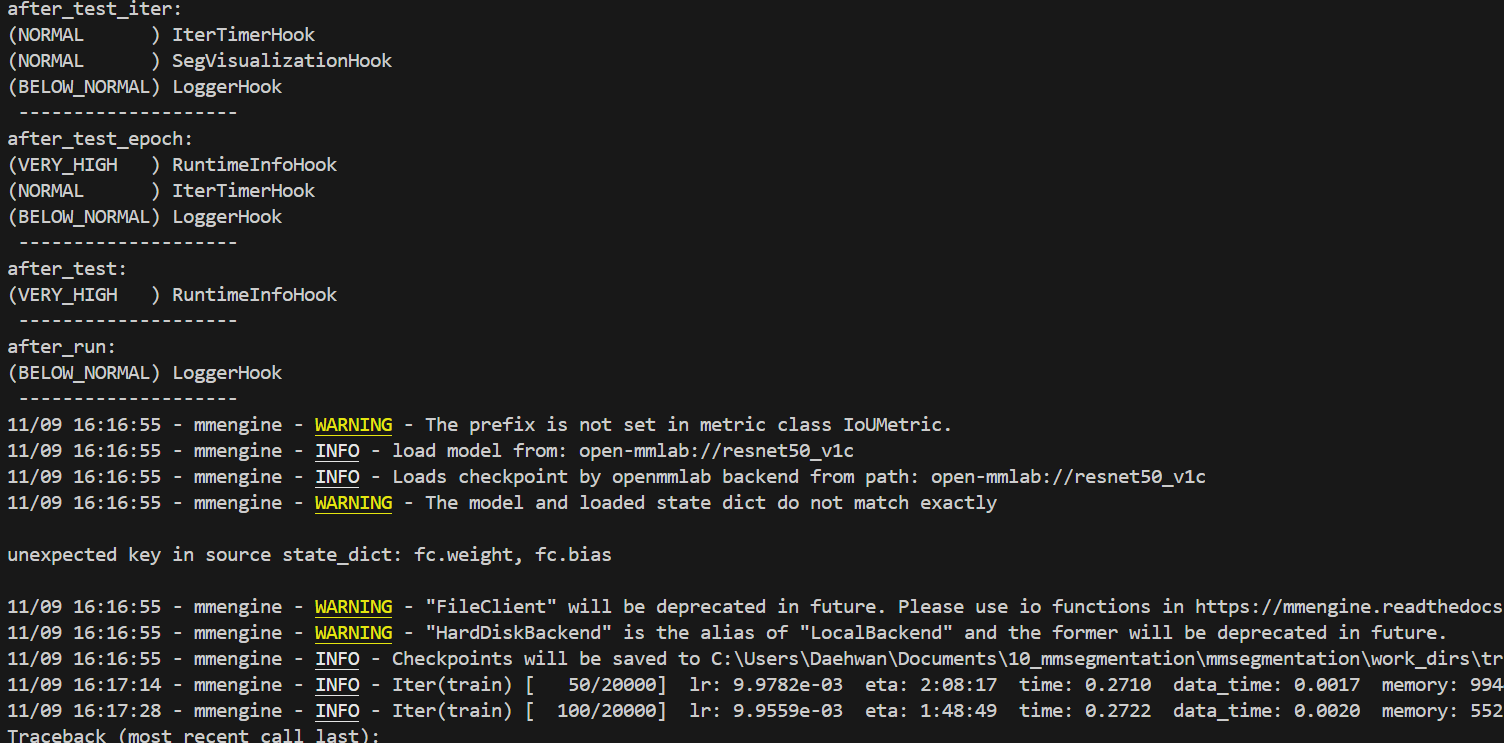
학습이 정상적으로 진행 된다면 아래 이미지를 볼 수 있다.
마무리
이와 같이 기본 설정 파일을 불러와 수정함으로써, 사용자는 간편하게 모델 학습을 시작할 수 있다. 중요한 것은 설정 파일들의 구조와 역할을 이해하는 것이다. 처음에는 복잡해 보일 수 있지만, 직접 실행해 보고 구조를 파악하면 이해가 더 쉽다. 이렇게 학습을 진행하면서 각자의 상황에 맞게 설정 파일들을 수정해 나가면 된다.
이상합니다. 끝.
감사합니다.
'딥러닝 (Deep Learning) > [08] - 프로젝트' 카테고리의 다른 글
| [04 Segmentation] - Semantic Segmentation 대회에서 사용하는 방법들 (1) | 2024.11.23 |
|---|---|
| [04 Segmentation] - PyTorch 에서 메모리 부족할때 해결하는 방법! (Autocast, GradScaler) (0) | 2024.11.21 |
| [03 OCR] - 영수증 데이터 추가 방법 (5) | 2024.11.08 |
| [02 Object Detection] - MMdetection train/val 학습 방법 (7) | 2024.10.27 |
| [02 Object Detection] - MMdetection 설치 및 기본사용법 (6) | 2024.10.26 |