Receptive Field 란??
Receptive field는 신경망에서 특정 뉴런이 입력 데이터(예: 이미지)에서 보는 영역을 의미한다. 예를 들어, 이미지의 한 픽셀을 처리하는 뉴런이 주변 3×3 영역을 참조한다면, 이 3×3 영역이 해당 뉴런의 receptive field이다. 이는 입력 데이터를 이해하고 정보를 추출하는 데 매우 중요한 개념이다.

Receptive Field가 작은 경우
이미지에서 빨간 점을 중심으로 segmentation을 수행할 때, 작은 receptive field는 새의 일부 정보만 포함한다.
결과적으로, 모델이 전체 문맥이나 객체의 구조를 이해하지 못하고, 부분적인 정보에만 의존하여 정확도가 떨어질 수 있다.
Receptive Field가 큰 경우
반대로, 큰 receptive field는 새 전체에 대한 정보를 모두 포함한다.
이는 모델이 새의 전체적인 구조와 문맥을 파악하도록 도와 더 정확한 학습과 예측을 가능하게 한다.
Receptive field가 클수록 객체의 전반적인 정보를 포괄적으로 다룰 수 있어 더 좋은 학습 모델을 만들 수 있다. 이는 특히 객체의 경계나 세부적인 구분이 중요한 segmentation 작업에서 매우 중요한 요소이다.
Receptive Field 확장한 모델 DeepLab v1
1. 기존 Receptive Field
아래 그림은 기존의 ConvNet에서 사용하는 방식으로, receptive field를 확장하기는 하지만 제한적이다. 즉, 단순히 3×3 필터를 연속적으로 적용해서 receptive field를 넓히는 전통적인 방법이다. 이건 딥러닝 초기 모델인 DeconvNet이나 기본 CNN 아키텍처에서 많이 사용되었던 방식이다.

위의 그림에서 receptive field 5x5 인데 어떻게 계산이 되는지 생각해보자
첫 번째 3×3 필터는 입력 이미지(10x10)에서 3×3 크기의 영역을 본다.
이 단계에서 receptive field는 단순히 3×3이다.
두 번째 Conv에서도 3×3 필터를 사용하지만, 이 필터는 첫 번째 Conv에서 나온 feature map을 대상으로 연산한다.
즉, 첫 번째 feature map의 3x3 에서 두번째 필터 3×3 필터를 적용해서 보고 있다는 것이다.
따라서 두 번째 Conv: 3×3 필터의 양쪽으로 1픽셀씩 확장되어
최종족으로 3+2 (5x5) 형태가 되는것이다.
2. Max Pooling을 활용한 Receptive Field 확장
맨위에서 언급한거처럼 Recptive Field를 확장시키면 더 좋은 학습 모델을 만들 수 있다고 했다.
확장시키기 위해 기존 Conv 방식 사이에 Max-pooling 을 넣어서 확장시켰다

첫 번째 Conv 연산 (3×3 필터)
입력 데이터는 10×10 크기이며, 첫 번째 Conv 레이어에서 3×3 필터를 적용한다.
이 Conv 연산을 통해 8×8 크기의 첫 번째 feature map이 생성된다.
이 단계에서 receptive field는 3×3이다.
Max Pooling (2×2, Stride=2)
첫 번째 feature map(8x8)에 Max Pooling을 적용한다.
Max Pooling은 픽셀 그룹(2×2)에서 가장 큰 값을 선택하여 데이터 크기를 줄이는 연산이다.
이 연산을 통해 feature map은 4×4로 크기가 줄어든다.
이때 receptive field는 한 번의 Max Pooling으로 인해 2배로 확장된다.
즉, Conv 연산 후 3×3이었던 receptive field가 6×6으로 확장된다.
Max pooling 을 압축하지 않았던 데이터를 봤을때는 3x3 이지만,
Max pooling 으로 압축한 피쳐맵의 receptive filed를 봐서 6x6 으로 확장 된 것이다.
두 번째 Conv 연산 (3×3 필터)
Max Pooling으로 크기가 4×4로 줄어든 feature map에 다시 3×3 필터를 적용한다.
이 Conv 연산은 receptive field를 8×8로 확장한다.
Conv 연산은 이전 receptive field(6×6)에 현재 필터 크기(3×3)에서 겹치는 부분(2칸)을 더해 8×8이 되는 방식이다.
Max Pooling을 사용하면 feature map의 크기는 줄어들지만, receptive field는 더 넓어진다.
즉, 더 적은 픽셀로 더 넓은 정보를 볼 수 있게 된다는 점이 Max Pooling의 중요한 효과이다.
그러나 Conv → Max Pooling → Conv를 반복적으로 적용하면 효율적으로 receptive field를 넓힐 수 있다. 하지만 이 방식은 feature map의 해상도(resolution)가 낮아지는 문제점이 발생한다. 이러한 문제를 해결하기 위해 도입된 기술이 바로 Dilated Convolution(팽창 합성곱)이다. 이번 글에서는 이 기법이 어떤 문제를 해결하며, 어떤 원리로 동작하는지 알아보자.
Dilated Convolution
전통적인 방식에서는 receptive field를 넓히기 위해 Max Pooling과 stride를 사용하여 feature map 크기를 줄이는 방법을 활용한다. 하지만 이러한 방식은 아래와 같은 문제를 초래한다.
1. Low Feature Resolution
Max Pooling과 stride는 feature map 크기를 줄이므로, 이미지의 세부적인 정보가 손실될 가능성이 높아진다.
특히, 픽셀 단위의 정확도가 중요한 작업(예: Semantic Segmentation)에서는 큰 단점으로 작용한다.
2. 문맥 정보 부족
단순히 Conv 레이어를 쌓아서는 receptive field 확장이 제한적이다. 따라서 더 넓은 문맥 정보를 학습하기 어렵다.
Dilated Convolution의 원리
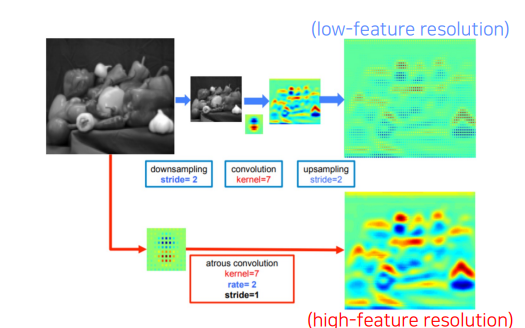
Dilated Convolution은 커널 간격(dilation rate)을 늘려 receptive field를 확장하는 방법이다.
이 방식은 해상도를 유지하면서도 더 넓은 영역의 정보를 학습할 수 있다.
Dilated Convolution의 특징
- 간격 있는 커널 적용
- 일반적인 3×3 커널에서는 모든 픽셀에 필터를 적용하지만, dilated convolution은 픽셀 사이에 간격(dilation rate)을 추가로 둔다.
- 예: dilation rate=2일 때, 3×3 커널은 5×5 크기의 receptive field와 동일한 정보를 본다.
- Receptive Field 확장
- 커널의 크기는 유지하면서, receptive field를 더 넓게 확장할 수 있다.
- 예: dilation rate=2이면 기존 3×3 필터가 5×5 크기의 정보를 학습하며, dilation rate=3이면 7×7 크기를 본다.
- Feature Resolution 유지
- Max Pooling이나 stride를 사용하지 않으므로, feature map의 해상도를 유지하면서도 receptive field를 확장할 수 있다.
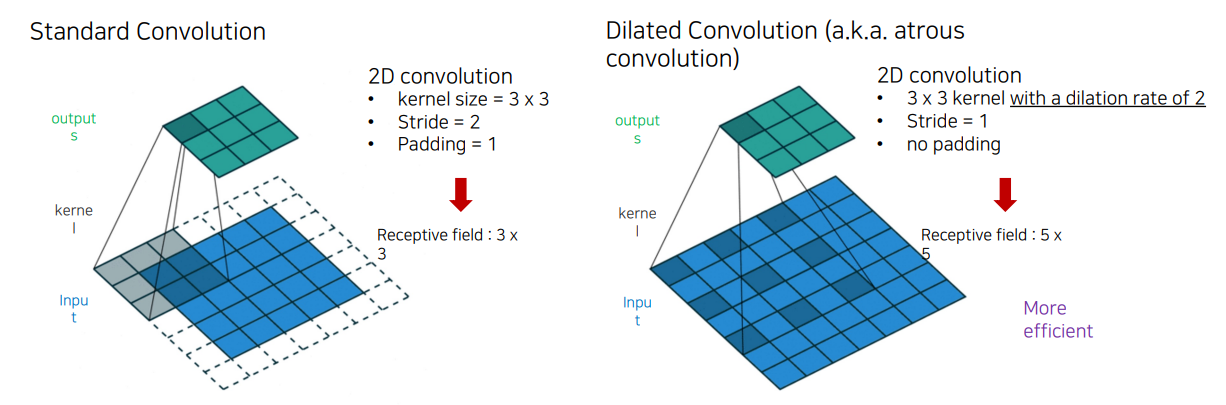
핵심 차이점
| Receptive Field 크기 | 작음 (3x3) | 큼 (5x5) |
| 출력 해상도 | Stride=2로 인해 해상도가 낮아짐 | Stride=1로 인해 해상도를 유지함 |
| 계산 효율성 | 좁은 영역에 한정된 정보 학습 | 더 넓은 영역을 더 적은 연산으로 학습 |
Dilated Convolution이 해상도를 유지하면서도 Receptive Field를 확장할 수 있다는 것을 보여준다.
- Standard Convolution보다 더 넓은 문맥 정보를 학습할 수 있다.
- Downsampling으로 인해 발생하는 세부 정보 손실을 방지할 수 있다.
Dilated Convolution은 Semantic Segmentation과 같은 픽셀 단위 정밀도가 필요한 작업에서 특히 유용하다.
Dense CRF (Conditional Random Field): 객체 경계를 복원하는 기술
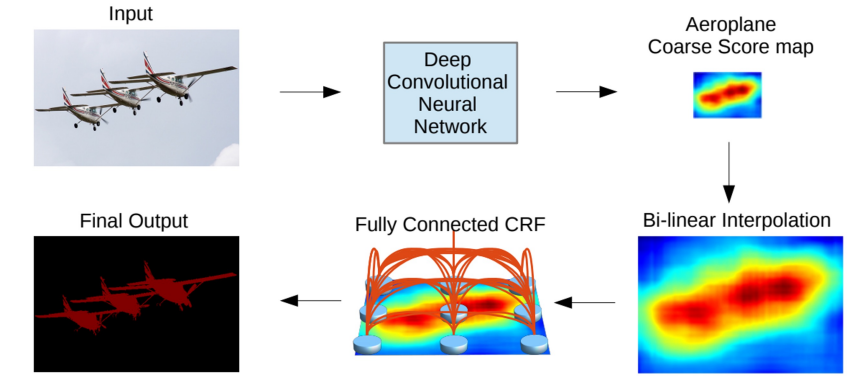
Dense CRF(Conditional Random Field)는 픽셀 간의 관계를 모델링하여 객체 경계를 정교하게 복원하는 데 사용되는 기술이다. 주로 Semantic Segmentation과 같은 픽셀 단위의 예측 문제에서, 부드럽고 세밀한 결과를 얻기 위해 활용된다. 이번에는 CRF의 개념, 원리, 그리고 딥러닝 모델에서의 활용 방식을 알아보자.
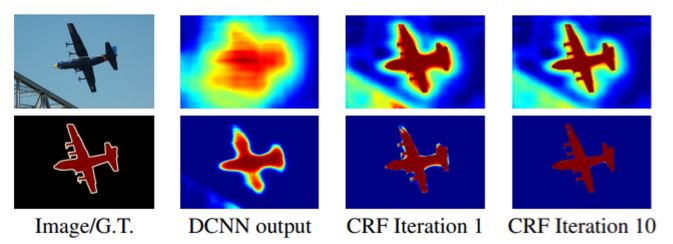
CRF는 확률 그래프 모델(Probabilistic Graphical Model)의 일종으로, 픽셀 간의 조건부 확률을 기반으로 각 픽셀이 어느 클래스에 속하는지 예측한다.
쉽게 말해, 인접 픽셀들이 비슷한 클래스에 속할 가능성을 높이고, 다른 객체의 픽셀과는 구분되도록 학습하는 모델이다. 위의 그림은 CRF 적용 전후 사진을 보여주는 예시이다.
좀 더 구체적으로 보면,
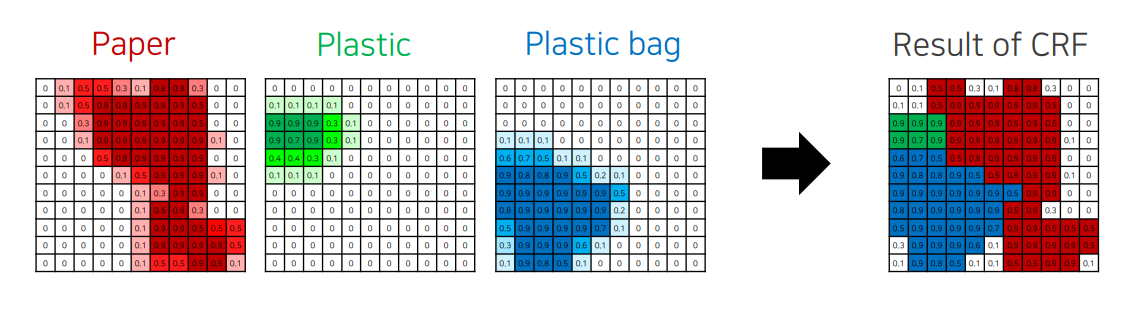
1.예제 시나리오
입력 이미지는 재활용품 분류 작업(예: Paper, Plastic, Plastic Bag)을 수행.
딥러닝 모델의 출력은 각 픽셀에 대해 해당 클래스에 속할 확률을 나타내는 feature map.
예) "Plastic Bag"일 확률이 0.9인 픽셀, "Paper"일 확률이 0.5인 픽셀 등.
2. 문제 상황
딥러닝 모델의 예측 결과는 클래스 경계가 흐릿하거나, 디테일이 부족하다.
예를 들어, "Plastic Bag"이어야 할 영역이 주변 픽셀의 노이즈로 인해 잘못 예측될 수 있다.
3. CRF의 해결 방식
클래스 확률 맵 생성
모델이 예측한 각 클래스의 확률 값을 기반으로 확률 맵(feature map)을 만든다.
예: Paper, Plastic, Plastic Bag 각각의 확률 맵.
픽셀 간 관계 최적화
CRF는 인접 픽셀의 색상, 위치, 클래스 확률 정보를 사용해 관계를 모델링
비슷한 색상이나 공간적으로 가까운 픽셀은 같은 클래스에 속할 가능성을 높이고, 그렇지 않은 픽셀은 다르게 조정
최종 결과 도출
CRF는 픽셀 간 최적화를 통해 노이즈를 제거하고, 경계를 더욱 선명하게 만든다.
결과적으로, "Plastic Bag"과 "Paper"의 경계가 명확히 구분되며, 디테일이 살아난 최종 분류 결과를 얻는다.
CRF는 Semantic Segmentation 작업에서 모델 예측 결과를 더욱 정교하게 만드는 핵심 후처리 기법입니다.
픽셀 간 관계를 기반으로 경계를 복원하고, 잘못된 픽셀 값을 제거하여 디테일이 살아있는 결과를 만들어낸다.
지금까지 배운 내용 기반으로 실제 모델 DeepLap v1, v2 에 대해서 다음 블로그에 언급하겠습니다.
DeepLab v1 은 CRF 를 적용했고,
DeepLab v2 는 Dilated Convolition 을 적용 했습니다.
다음 포스팅에서 이어서 작성하겠습니다.
감사합니다.
끝.
'의료 AI > [02] - 모델' 카테고리의 다른 글
| U-Net3++ (0) | 2024.11.22 |
|---|---|
| DeepLab v1 아키텍쳐 분석 (1) | 2024.11.20 |
| SegNet의 아키텍처 (2) | 2024.11.18 |
| [04] - FC DenseNet 이란? (0) | 2024.11.15 |
| [03] - 빠르면서도 정확한 SegNet (0) | 2024.11.14 |




댓글