Faster R-CNN 의 개념을 이해하기 전에
전에 블로그에서 설명했던 개념들을 먼저 간략하게 정리하고 설명하겠습니다.
1. Region Proposal (객체 후보 영역)
- Region Proposal은 이미지에서 객체가 있을 법한 위치를 미리 추출하는 단계입니다.
- 초기 모델인 R-CNN은 이를 위해 Selective Search라는 기법을 사용했지만, Faster R-CNN에서는 이를 학습 가능한 네트워크인 Region Proposal Network (RPN)으로 대체합니다
2. RoI Pooling (Region of Interest Pooling)
- RoI Pooling은 Fast R-CNN에서 도입된 기법으로, 다양한 크기의 후보 영역(Region Proposals)을 고정된 크기의 벡터로 변환하는 작업을 합니다.
- 이를 통해 CNN이 모든 후보 영역을 동일한 크기로 처리할 수 있게 하고, 연산 효율성을 극대화합니다.
자세한 내용은 아래 링크 확인해주세요!
https://ai-bt.tistory.com/entry/02-2-Stage-Detectors
[02] R-CNN, SPPNet, Fast R-CNN
1. R-CNN R-CNN 의 경우는 아래의 논문리뷰에서 자세히 설명했습니다.아래 링크를 참고 부탁드립니다. https://ai-bt.tistory.com/entry/R-CNN-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0 R-CNN 논문 리뷰서론딥러닝의 발전
ai-bt.tistory.com
1. Fast R-CNN 과 Faster R-CNN 구조
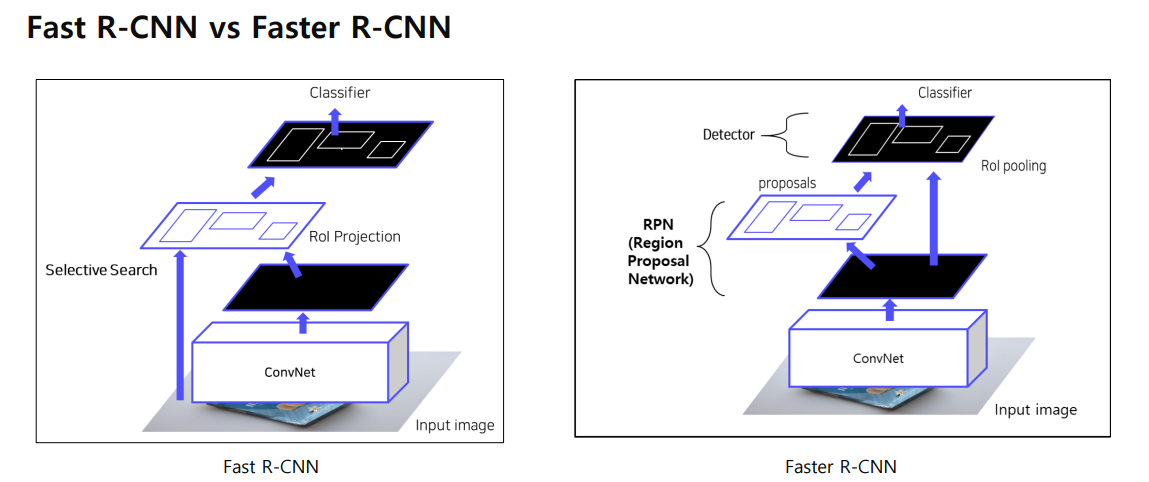
Fast R-CNN
- ConvNet
- 입력 이미지는 먼저 ConvNet(CNN)에 통과되어 feature map을 생성합니다. 이 feature map은 이미지의 중요한 공간적 특징을 압축한 결과입니다.
- Selective Search
- Fast R-CNN에서는 객체 후보 영역(Region of Interest, RoI)을 Selective Search라는 방법을 사용해 추출합니다.
- Selective Search는 이미지에서 2000개의 객체 후보 영역을 제안합니다. 하지만 이 과정은 CPU에서 처리되며, 매우 시간이 많이 소요됩니다.
- RoI Projection
- Selective Search로 추출된 RoI는 RoI Projection을 통해 feature map에 대응되도록 투영됩니다.
- 후보 영역들이 원본 이미지에서 차지하는 크기와 위치를 feature map 상에서도 동일하게 맞춰 투영하는 과정입니다.
- RoI Pooling Layer
- 투영된 RoI는 RoI Pooling Layer를 통해 고정된 크기의 벡터로 변환됩니다. 이때 다양한 크기의 RoI가 동일한 크기(7x7)로 변환됩니다.
- RoI Pooling은 CNN을 다시 통과시키지 않고, feature map에서 각 RoI를 고정된 크기로 변환해 처리할 수 있어 연산 속도가 크게 향상됩니다.
- Classifier
- RoI Pooling을 통해 변환된 고정된 크기의 벡터는 Fully Connected Layer와 Softmax Classifier를 통해 객체의 클래스를 예측하고, 바운딩 박스의 위치를 미세 조정합니다.
Faster R-CNN
- ConvNet
- 입력 이미지는 마찬가지로 ConvNet을 통과하여 feature map을 생성합니다. 이 단계는 Fast R-CNN과 동일합니다.
- Region Proposal Network (RPN)
- Faster R-CNN의 가장 큰 차이점이자 핵심 혁신은 Region Proposal Network (RPN)입니다. Selective Search 대신에, RPN을 통해 학습 가능한 방식으로 객체 후보 영역을 추출합니다.
- RPN은 ConvNet을 통과한 feature map에서 바로 객체가 있을 법한 후보 영역을 제안합니다. 이 과정은 CNN과 통합된 구조에서 이루어지며, GPU에서 학습되기 때문에 연산 속도와 효율성이 크게 향상되었습니다.
- RPN은 이미지의 여러 위치에서 작은 네트워크를 사용해 객체가 있을 가능성이 높은 영역(proposals)을 제안하고, 이 제안된 후보 영역은 후속 단계에서 사용됩니다.
- RoI Pooling
- RPN에서 제안된 후보 영역은 RoI Pooling Layer를 통해 고정된 크기의 벡터로 변환됩니다. 이 과정은 Fast R-CNN과 동일하게 동작합니다.
- Classifier
- RoI Pooling을 거친 고정된 크기의 벡터는 Fully Connected Layer와 Softmax Classifier를 통과해 객체 분류와 바운딩 박스 회귀를 수행합니다.
2. RPN (Region Proposal Network)
1) Anchor Box

기존 Fast R-CNN Selective Search 를 통해서 RoI Projection 을 해서 RoI 를 뽑아냈다.
Faster R-CNN 에서는 Selective Search 사라지고, Anchor box 개념을 도입했습니다.
각 셀마다 다양한 크기의 box 혹은 다양한 크기의 비율을 가진 box 미리 정의를 할 수있다.
이렇게 정의된 box 가 Anchor Box 입니다. (위의 이미지 참고)
각 셀마다 n개의 Anchor Box를 추출 할 수 있습니다.
현재 상황을 정리하면,
이미지가 ConvNet 를 통과해서 feature 맵이 추출 되고.
각 feature map 의 각 Cell 마다
다양한 스케일과 비율을 가진 K 개의 Anchor Box 가 있는 상황이다
2) RPN

Feature map 이 만약 64x64 이고, 9개의 Anchor box 를 사용하게 된다면,
64x64x9 = 36,000개의 ROI 가 생기게 된다.
근데 이렇게 되면 Anchor box 가 너무 많다.
그리고 각 Anchor box 가 정확한 객체를 포함하고 있는지 모른다.
RPN 이 하는 일은
Anchor box 객체가 포함하고 있는지 예측하는 판단 근거를 주고
만약 객체를 포함하고 있다면,
구체적으로 Anchor box 를 어떻게 미세조정을 하는 것이다.
위의 그림에서 RPN 은 예측을 위해서 각 픽셀마다 2개의 헤드를 통과한다.
K개의 Ankor box가 있을때,
1) 각 Ankor box 가 객체를 포함하고 있는지 아닌지 예측하는 classfication head
2) 각 Anchor box 의 크기를 미세조정하는 coordinates head
Faster R-CNN 에서는 3가지 스케일, 3가지 비율을 가진 9개 Anchor box 를 이용한다.
예시를 통해서 한번 더 이해를 해보자.
1) 원본이미지의 CNN 에서 나온 feature map 를 input으로 받는다 (H,W,C)
2) 3x3 Conv 수행하여 intermediate layer 생성

3) 1x1 Conv 수행하여 binary classification 수행

18개 이유는
object 인지 아닌지 2가지
Anchor box 9개
2x9 = 18 채널로 Conv 연산을 해준다.
그래서 9개 Anchor box 가 객체인지 아닌지 채널에 정보가 포함되어 있는 것이다.
4) 1x1 conv 수행하여 bounding box regression 수행

36개 이유는
각 Anchor box 별로 중심점의 좌표 (x,y)
가로, 세로 길이 (w,h)
그래서 총 4가지이고 4x9 = 36 채널이 된다.

다시 한번 정리를 하면,
input image 이미지가 백본을 통과하고 피쳐맵이 존재하고 (64 64 512)
각 픽셀 별로 9개의 앵커박스가 존재하고
그 9개의 anchor box 가
객체를 포함하는지 예측하고 clssifcation 헤드
box 는 box 의 위치를 이동시켜주는 미세조정해주는 box 헤드
그렇게 도ㅒㅆ을때 classfication 통과ㅣ하면
약 36000 각 anchor box 스코어가 나온다.
그 다음은 스코어를 예측해서
스코어를 기준으로 쭉 정렬 해서
쭉 정렬해서 탑 n개의 앵커박스를 추출하고 셀렉트 할 수 있다.
셀렉트된 anchor box 를 가지고 사이즈 미세조정을한다.
1. Input Image와 Feature Map 생성
- 입력 이미지(400x400x3)는 Backbone Network를 통과해 Feature Map을 생성합니다.
- 예를 들어, 64x64x512 크기의 Feature Map이 생성됩니다. 이 feature map은 이미지의 중요한 공간적 특징을 담고 있습니다.
2. Anchor Box 생성
- Anchor Box Generator는 Feature Map 상의 각 픽셀에서 9개의 Anchor Boxes를 생성합니다.
3. 클래스 및 박스 예측 (Classification & Box Prediction)
- Classification Head
각 Anchor Box가 객체를 포함하는지 여부를 예측하는 Classification Head를 통해 64x64x9x2 크기의 결과를 얻게 됩니다.- 2개의 스코어는 객체가 있을 확률과 없을 확률을 나타냅니다.
- 따라서, 전체적으로 약 36,000개의 Anchor Box에 대한 스코어가 나오게 됩니다.
- Box Prediction Head
Classification Head 에서 객체가 포함한 것을 가지고 각 Anchor Box의 좌표를 미세 조정하는 Box Prediction Head를 통해, 64x64x9x4 크기의 박스 좌표를 예측하게 됩니다. 이 좌표값은 객체의 정확한 위치를 예측하여, 바운딩 박스의 위치를 조정합니다.
4. Top N Anchor Box 선택
- Class Prediction 결과로 나온 Anchor Box의 스코어를 기준으로 정렬합니다.
- 정렬된 스코어 중에서 가장 높은 N개의 Anchor Box를 선택합니다. 이 과정에서 비효율적인 바운딩 박스는 제거됩니다.
5. 박스 좌표 미세 조정
- 선택된 Top N Anchor Box는 Box Prediction에서 예측한 좌표값을 기반으로
바운딩 박스의 위치를 미세 조정합니다. - 이로써, 최종적으로 정확한 위치의 후보 영역이 결정됩니다.
3) NMS
1. RPN에서 중복된 Proposals 제거
RPN (Region Proposal Network)는 이미지에서 여러 객체 후보 영역(Region Proposals)을 제안합니다. 이때, 여러 Anchor Box가 겹치는 경우가 많아 중복된 후보 영역이 다수 생성될 수 있습니다. NMS는 이러한 중복된 Proposals 중에서 가장 적합한 하나의 박스만 남기고 나머지를 제거하는 역할을 합니다.
2. Class Score를 기준으로 Proposals 분류
NMS는 먼저 Class Score (객체일 가능성)을 기준으로 각 바운딩 박스를 정렬합니다. 이 과정에서 객체를 포함할 가능성이 높은 바운딩 박스부터 순서대로 처리합니다.
Class Score 예시:
- 예를 들어, 이미지 내에서 객체가 있을 가능성이 높은 상위 몇 개의 박스를 Class Score로 정렬합니다.
- 가장 높은 점수를 받은 바운딩 박스부터 객체로 인정하고, 그와 겹치는 다른 바운딩 박스들을 제거하는 방식입니다.

bb1 기준으로 IoU score 를 계산한다.
3. IoU (Intersection over Union)를 기준으로 중복된 Proposals 제거
NMS는 IoU (Intersection over Union)를 이용해 바운딩 박스가 얼마나 겹치는지를 계산합니다. IoU는 두 바운딩 박스 간의 겹치는 영역을 두 박스의 전체 영역에 대한 비율로 나타냅니다.
- IoU 값이 0.7 이상인 Proposals는 중복된 영역으로 간주합니다.
- 이를 통해, 가장 높은 Class Score를 받은 바운딩 박스와 IoU 값이 0.7 이상인 다른 박스들을 중복된 영역으로 판단하고 제거합니다.
예시:
- 하나의 객체를 여러 박스가 감싸고 있을 때, 가장 정확한 박스 하나만 남기고, 나머지 박스들은 제거합니다.
- IoU가 0.7 이상인 바운딩 박스들은 너무 많이 겹치는 것으로 판단되어 중복된 영역으로 처리됩니다.

NMS (Non-Maximum Suppression)는 객체 탐지에서 중복된 예측을 제거하고, 가장 신뢰할 수 있는 바운딩 박스만 남기는 매우 중요한 과정입니다. 이를 통해 모델은 더 정확한 객체 탐지를 수행할 수 있으며, 중복된 예측으로 인한 성능 저하를 방지합니다. IoU와 Class Score를 사용하여 중복된 영역을 정리하는 방식으로, 이미지 내의 객체를 효과적으로 탐지할 수 있게 됩니다.
지금까지 Faster R-CNN 에 대해서 설명했습니다.
감사합니다.
'AI Naver boost camp > [Week 07] - Object Detection' 카테고리의 다른 글
| [02] R-CNN, SPPNet, Fast R-CNN (0) | 2024.10.02 |
|---|---|
| [01] - Object Detection 정의와 Evaluation metric (평가지표) (3) | 2024.10.02 |


댓글