StratifiedKFold와 앙상블을 사용한 CIFAR-10 분류 모델 학습
이번 포스팅에서는 StratifiedKFold를 사용하여 CIFAR-10 데이터셋을 다루는 방법과, 각 폴드에서 학습한 모델들을 앙상블하여 최종 성능을 높이는 방법을 소개하겠습니다. StratifiedKFold는 데이터셋의 클래스 비율을 유지하면서 데이터를 여러 폴드로 나누기 때문에, 특히 데이터 불균형 문제를 해결하는 데 유용합니다.
1. 프로젝트 개요
우리는 CIFAR-10 데이터셋을 사용하여 이미지를 분류하는 작업을 수행할 것입니다. 이 데이터셋에는 10개의 클래스(예: 개구리, 고양이, 개 등)로 분류된 이미지가 있습니다. 각 클래스에서 고정된 수의 샘플을 선택한 후, StratifiedKFold를 사용하여 교차 검증을 진행합니다. 마지막으로 각 폴드에서 학습된 모델을 앙상블하여 최종 예측 성능을 평가합니다.
2. StratifiedKFold란?
StratifiedKFold는 교차 검증을 위한 방법 중 하나로, 데이터를 여러 개의 폴드(fold)로 나누고 각 폴드에서 모델을 학습하고 검증할 수 있게 도와줍니다. 일반적인 교차 검증 방법과 달리, StratifiedKFold는 각 폴드에 있는 데이터가 클래스 비율을 유지하도록 데이터를 나눕니다.
예를 들어, CIFAR-10 데이터셋에서 클래스별로 데이터가 불균형하다면, StratifiedKFold는 각 폴드가 원본 데이터셋의 클래스 분포를 유지하도록 데이터를 나눕니다. 이렇게 하면 학습과 검증이 데이터의 분포와 더 잘 맞도록 설계됩니다.
3. 데이터 준비 및 클래스별 샘플 선택
우선, CIFAR-10 데이터셋을 불러오고 각 클래스에서 일정 수의 샘플을 선택합니다. 이를 통해 각 클래스가 고르게 학습되도록 합니다.
# CIFAR-10 데이터셋 로드
train_data = datasets.CIFAR10(root="./data/", train=True, download=True)
test_data = datasets.CIFAR10(root="./data/", train=False, download=True)
# 각 클래스별로 30개씩 샘플
selected_train_data = select_samples_per_class(train_data, 30)
# 각 클래스별로 10개씩 샘플
selected_test_data = select_samples_per_class(test_data, 10)
위 코드에서 select_samples_per_class 함수는 각 클래스별로 지정된 개수만큼 데이터를 선택하여, CIFAR-10 데이터셋에서 부분집합을 만들어 줍니다.
4. CustomDataset 클래스와 모델 학습
CustomDataset 클래스는 데이터를 불러오고, 필요한 변환(transform)을 적용합니다. 학습용 데이터와 검증용 데이터를 Subset을 통해 폴드별로 나눈 후, DataLoader로 데이터를 배치 단)로 불러옵니다.
class CustomDataset(Dataset):
def __init__(self, data, is_train=True):
self.data = data
self.is_train = is_train
transform_list = []
if self.is_train:
transform_list = [
v2.RandomResizedCrop(size=(224, 224), antialias=True),
v2.RandomHorizontalFlip(p=0.5)
]
transform_list = transform_list + [
v2.PILToTensor(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]
self.transforms = v2.Compose(transform_list)
def __getitem__(self, idx):
image = self.data[idx][0]
label = self.data[idx][1]
image = self.transforms(image)
return image, label
def __len__(self):
return len(self.data)
train_dataset = CustomDataset(selected_train_data, is_train=True)
test_dataset = CustomDataset(selected_test_data, is_train=False)
print(len(train_dataset)) # 클래스 10 * 30 = 300
print(len(test_dataset)) # 클래스 10 * 10 = 100
train_dataloader = DataLoader(train_dataset, batch_size=16, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=16, shuffle=False, drop_last=False)
그리고, CustomModel 클래스는 사전 학습된 ResNet18을 사용하여 CIFAR-10을 분류하는 모델입니다. 마지막 레이어는 CIFAR-10의 클래스 수에 맞게 수정되었습니다.
class CustomModel(nn.Module):
def __init__(self):
super(CustomModel, self).__init__()
self.model = resnet18(pretrained=True)
self.model.fc = nn.Linear(self.model.fc.in_features, 10)
5. StratifiedKFold를 통한 교차 검증
이제 StratifiedKFold를 사용하여 데이터를 5개의 폴드로 나누고, 각 폴드에서 학습과 검증을 진행합니다. 각 폴드마다 학습된 모델을 저장하여 앙상블에 활용할 것입니다.
n_splits = 5
skf = StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=42)
# 'selected_train_data'에서 레이블만 추출하여 리스트 생성
labels = [selected_train_data.dataset.targets[idx] for idx in selected_train_data.indices]
models = []
# 교차 검증을 통해 각 Fold에 대한 학습 및 검증을 실행
for fold, (train_idx, val_idx) in enumerate(skf.split(selected_train_data.indices, labels)):
print(f'Fold {fold+1}')
# Subset 학습 및 검증 데이터 분리
train_subset = Subset(selected_train_data, train_idx)
val_subset = Subset(selected_train_data, val_idx)
train_dataset = CustomDataset(train_subset, is_train=True)
val_dataset = CustomDataset(val_subset, is_train=False)
# DataLoader 생성
train_dataloader = DataLoader(train_dataset, batch_size=16, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=16, shuffle=False, drop_last=False)
model = CustomModel().to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
epochs = 2
for epoch in range(epochs):
print(f"Epoch {epoch+1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer, device)
test_loop(val_dataloader, model, loss_fn, device)
models.append(model)
StratifiedKFold는 각 폴드에서 학습과 검증을 반복하며, 각 폴드마다 학습된 모델을 models 리스트에 저장합니다.
6. 앙상블 예측
이제 각 폴드에서 학습된 모델들을 앙상블하여 테스트 데이터셋에 대한 예측을 수행합니다. 앙상블을 사용하면 개별 모델보다 더 높은 성능을 기대할 수 있습니다.
def ensemble_predict(models, dataloader, device):
predictions = np.zeros((len(dataloader.dataset), 10))
for model in models:
model.eval()
with torch.no_grad():
fold_predictions = []
for X, _ in dataloader:
X = X.to(device)
pred = model(X)
fold_predictions.append(pred.cpu().numpy())
fold_predictions = np.vstack(fold_predictions)
predictions += fold_predictions
return predictions
ensemble_predict 함수는 각 모델의 예측값을 합산한 후, 최종적으로 가장 높은 확률을 가진 클래스를 선택하여 반환합니다.
7. 최종 성능 평가
앙상블된 모델을 사용해 테스트 데이터셋에 대한 최종 예측을 수행하고, 정확도를 계산합니다.
test_predictions = ensemble_predict(models, test_dataloader, device)
# 테스트 데이터 평가
final_test_labels = np.array([y for _, y in selected_test_data])
test_accuracy = accuracy(torch.tensor(test_predictions), torch.tensor(final_test_labels))
print(f"Test Accuracy: {test_accuracy.item()*100:.2f}%")
최종적으로 각 폴드에서 학습된 모델을 앙상블한 결과, 테스트 데이터에 대한 예측 정확도를 확인할 수 있습니다.
8. 결론
StratifiedKFold를 사용한 교차 검증은 불균형한 데이터셋에서 특히 유용하며, 각 폴드에서의 성능 평가를 통해 모델이 과적합되지 않도록 도와줍니다. 또한, 각 폴드에서 학습한 모델들을 앙상블하면 개별 모델보다 더 나은 성능을 얻을 수 있습니다.
이번 포스팅에서는 CIFAR-10 데이터셋을 사용해 StratifiedKFold 교차 검증과 앙상블 방법을 적용해 보았습니다. 이 방법을 통해 더 높은 예측 성능을 달성할 수 있었으며, 이는 모델의 일반화 능력을 향상시키는 중요한 방법론입니다.
9. 정리 및 이해
1) 폴드 나누기:
- 이 부분에서 StratifiedKFold가 데이터를 train_idx(학습 데이터 인덱스)와 val_idx(검증 데이터 인덱스)로 나누어 줍니다.
- 교차 검증에서는 데이터셋을 k개의 폴드로 나누고, 각 폴드마다 학습과 검증을 진행합니다. 예를 들어, 5-fold 교차 검증이라면 전체 데이터셋을 5등분하여 각 폴드마다 학습을 80% 데이터로, 검증을 20% 데이터로 진행합니다.
for fold, (train_idx, val_idx) in enumerate(skf.split(selected_train_data.indices, labels)):
print(f'Fold {fold+1}')
2) 폴드마다 다른 학습 및 검증 데이터 사용:
- 각 폴드에 대해 train_subset과 val_subset을 생성하여 학습 및 검증 데이터를 나누어 줍니다.
- 폴드 1에서는 첫 번째 폴드를 검증 데이터로 사용하고 나머지 4개를 학습 데이터로 사용합니다. 폴드 2에서는 두 번째 폴드를 검증 데이터로 사용하고, 나머지 4개 폴드를 학습 데이터로 사용하는 방식으로 반복됩니다.
train_subset = Subset(selected_train_data, train_idx)
val_subset = Subset(selected_train_data, val_idx)
3) 데이터셋 생성:
- 학습과 검증에 사용할 데이터를 CustomDataset을 통해 생성하고, 각 폴드마다 이를 DataLoader에 넣어 학습에 사용할 준비를 합니다.
train_dataset = CustomDataset(train_subset, is_train=True)
val_dataset = CustomDataset(val_subset, is_train=False)
4) 모델 학습 및 검증:
- 각 폴드에서 학습 데이터를 사용해 모델을 학습하고, 검증 데이터를 사용해 성능을 평가합니다. 이 과정을 폴드마다 반복합니다.
for epoch in range(epochs):
train_loop(train_dataloader, model, loss_fn, optimizer, device)
test_loop(val_dataloader, model, loss_fn, device)
5) 모델 저장:
- 각 폴드에서 학습된 모델을 models 리스트에 저장합니다. 나중에 이 모델들을 사용해 앙상블을 수행합니다.
예시)
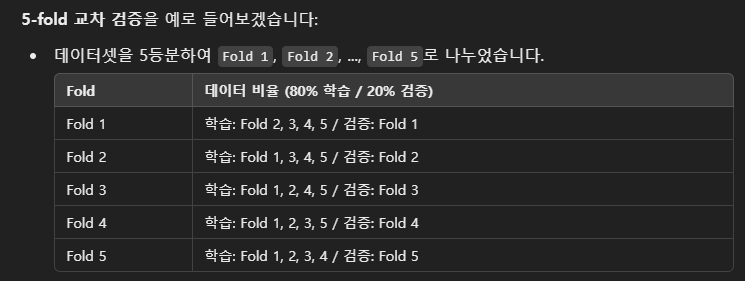
교차 검증의 장점
- 데이터 활용 극대화:
- 모든 데이터가 한 번씩 검증에 사용되므로, 데이터셋이 작더라도 데이터를 최대한 효율적으로 활용할 수 있습니다.
- 모든 샘플이 검증에 사용되기 때문에 과적합 방지에 도움이 됩니다.
- 일반화 성능 향상:
- 모델이 특정 데이터에만 잘 동작하지 않도록, 다양한 데이터에 대해 학습하고 검증을 수행함으로써 모델의 일반화 성능이 향상됩니다.
- 여러 번의 검증을 거치기 때문에 모델이 한 번의 테스트로 잘못된 결론에 도달할 가능성이 낮습니다.
- 평가의 신뢰성:
- 단일 학습-검증 데이터 분할로 얻은 평가 결과는 데이터 분할에 따라 편향될 수 있습니다. 하지만 교차 검증에서는 여러 번의 평가 결과를 평균화하여 더 신뢰할 수 있는 성능 평가가 가능합니다.
- 과적합 방지:
- 한 번의 학습으로 모델이 특정 학습 데이터에 과적합하는 것을 방지할 수 있습니다. 다양한 학습 데이터와 검증 데이터를 사용하여 모델을 학습하고 평가하게 됩니다.
요약
코드에서 진행된 것은 5-fold 교차 검증으로, 데이터를 5개의 폴드로 나누고, 각 폴드마다 학습과 검증을 진행합니다. 이 방식은 데이터를 최대한 효율적으로 활용하고, 모델의 일반화 성능을 높이는 데 유리합니다.
'딥러닝 (Deep Learning) > [04] - 학습 및 최적화' 카테고리의 다른 글
| 딥러닝 학습률(Learning Rate) 종류와 설정 방법 (2) | 2024.11.17 |
|---|---|
| Pytorch에서 Learning Rate(LR) 스케줄링 다양한 기법 (1) | 2024.09.30 |
| 활성화함수 (Activation funtion) (0) | 2024.08.16 |
| 경사하강법 - Gradient Desent (0) | 2024.08.13 |
| 경사하강법(GD) vs 확률적경사하강법(SGD) vs 미니 배치 경사하강법(MBGD) (0) | 2024.08.10 |