
Serving 의 구성
우선 Serving 은 크게 아래와 같은 구성으로 이루어진다.

1) 예측 서버
머신러닝 모델이 실제로 배치되어 예측을 수행하는 역할을 담당한다.
2) 데이터베이스
예측 서버에서 생성된 결과를 저장하고, 서비스 서버가 이를 활용할 수 있도록 제공한다.
3) 서비스 서버
사용자와 직접 상호작용하는 부분으로, 사용자 요청에 따라 데이터를 가져와 결과를 반환한다.
이 구성은 머신러닝 시스템 설계에서 기본적인 패턴으로, 배치(Batch) 또는 실시간(Online) 서빙에서 모두 활용될 수 있다. 상황에 따라 각 컴포넌트를 조정하여 더 최적화된 구조를 설계할 수 있다.
이제 Serving 종류에 대해서 알아보자.
Batch 패턴
우선 상황을 예시로 하나씩 살펴보자.
상황
- 영화 추천 모델을 개발 완료한 상태이다.
- 목표: 간단하고 비용 효율적인 방식으로 운영 환경에 배포하고자 한다
어떻게 하면 될까??
주기적으로 이 추천 모델을 사용자가 본 영화 데이터를 Input 으로 넣고
예측 Output 으로 나오는 사용자별 추천 영화를 DB 에 저장 후
추천 결과를 활용하는 서버쪽에서 DB 에 주기적으로 접근해 추천 결과를 노출하는 방식이다.
DB 를 중심으로 주고 받고가 형성되는 것이다.
즉,
- 예측 서버(모델): 사용자의 데이터를 받아 예측을 수행
- 데이터베이스(DB): 예측 결과를 저장하고 관리
- 서비스 서버: DB에서 결과를 가져와 사용자에게 노출
위와 같은 방식은 Batch 패턴에 해당한다.
주기적으로 데이터를 처리하고 저장하며, 서비스 서버가 이를 활용하도록 하는 것이다.
매일 밤 12시에 예측 서버에서 추천 결과를 생성해서
이 결과를 DB에 저장한 뒤, 서비스 서버가 다음 날 아침에 결과를 사용에게 노출하는 방식이다.
Batch 패턴에 핵심은
실시간성이 필요 없는 경우에 주기적으로 예측 결과를 DB 에 저장하고,
활용하는 쪾은 DB에서 결과를 읽어와서 사용하는 것이다.
1) Batch Serving 구조
위에는 구조 전체를 나타내는 다이어그램이다.
하나씩 살펴보자.
Job Management Server
배치 작업을 관리하는 서버이다.
이는 특정 주기나 조건에 따라 배치 작업(batch job)을 트리거(trigger) 한다.
예를 들어 시간표가 있는데 A는 매일 오전 9시에 업데이트 해야된다.
B는 오전 11시에 해야된다 이런식으로 주기나 조전에 따래 배치하는 것을 말한다.
주로 Apache Airflow 등을 사용한다.
Job
Job은 배치 처리의 실행 단위이다.
특정 조건(예: 시간 주기, 트리거)에 따라 실행되며, 입력 데이터를 받아 모델을 통해 예측 작업을 수행한다.
Python Script를 그냥 실행시키는 경우도 있고, Docker Image로 실행하는 경우도 존재한다.
Data
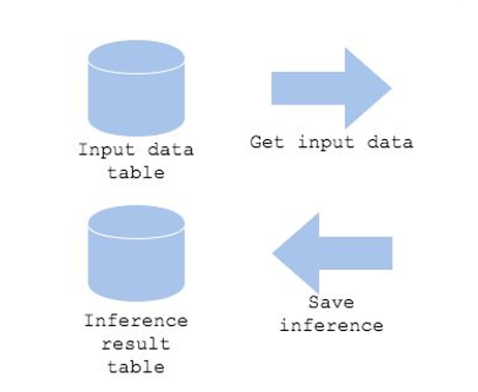
Input Data Table은 입력 데이터를 저장하는 데이터베이스이다. 배치 작업은 이 테이블에서 데이터를 가져온다.
Get Input Data는 Input Data Table에서 데이터를 가져오는 과정이다. 이는 배치 작업이 시작되기 전에 수행된다.
Save Inference는 모델의 예측 결과를 Inference Result Table에 저장하는 과정이다.
Inference Result Table은 예측 결과를 저장하는 데이터베이스이다. 이 테이블은 이후 서비스 서버가 결과를 조회하거나 활용할 수 있도록 데이터를 보관한다.
서비스에서 사용하는 DB(AWS RDS 등) 또는 데이터 웨어하우스에 저장하며,
서비스 서버에서도 데이터를 불러오는 스케줄링 Job이 존재(특정 시간 단위로 로드)
2) Batch 패턴 특징
단순함
- API 서버를 별도로 개발할 필요가 없어 구현이 간단하다.
- Job Management Server만 있으면 배치 작업 처리가 가능하다.
유연한 리소스 관리
- 시간이 오래 걸리는 Job에 서버 리소스를 추가 투입할 수 있다.
- 서버 리소스를 효율적으로 관리하여 비용을 절감할 수 있다.
대량 데이터 처리에 적합
- 한 번에 대량 데이터를 처리하는 데 최적화된 구조이다.
위의 특징을 파악하고 고민해야 될 점도 있다.
작업을 주기적으로 실행하기 위한 스케줄러(Apache Airflow)가 필요하다.
또한 실시간 처리가 필요한 경우 적합하지 않다.
그래서 Online Serving 으로 실시간 처리를 대응한다.
밑에서 한번 살펴보자
Web Single 패턴
Web Single 패턴은 실시간 요청을 처리하기 위해 설계된 패턴으로, 하나의 단위 작업(예측 요청)을 처리하는 방식이다.
기존의 Batch 패턴은 결과 반영까지 시간이 걸렸다.
영화 추천 결과가 DB에 1시간 단위로 업데이트가 되었는데, 유저 입장에서는 1시간을 기다려야한다.
이러한 기다림을 줄이기 위해
유저 요청이 들어올때 마다 API 서버가 모델에 데이터를 전달해 즉시 결과를 반환한다.
어떻게 구성 해야 할까?
모델이 항상 로드된 상태에서 요청을 처리할 수 있는 API 서버를 만들고,
예측이 필요한 서비스 서버가 이 API 서버에 직접 요청을 보낸다.
Web Single 패턴의 핵심은
API 서버에 모델을 포함시켜 배포할 수 있으며,
예측이 필요한 곳에서 즉시 요청을 보낼 수 있는 실시간 처리가 가능하다
Web Serving 구조
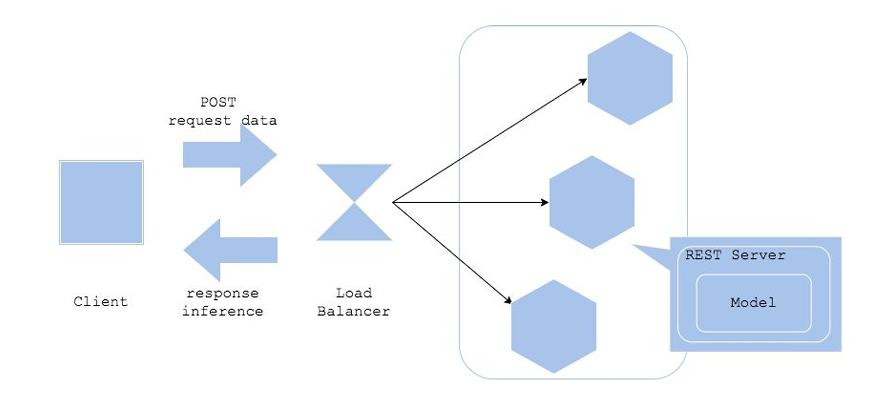
Client
- 클라이언트는 API를 통해 요청 데이터를 전달한다.
- 예측 결과를 실시간으로 받는다.
Load Balancer
- 트래픽을 분산시켜서 서버에 과부하를 걸리지 않도록 해준다.
- 대규모 요청이 들어올 경우 서버의 안정성을 유지한다.
- Nginx, Amazon ELB(Elastic Load Balancing) 등을 사용
REST Server
- 요청 데이터를 모델에 전달하고 결과를 반환하는 서버이다.
- 모델이 내장되어 예측 작업을 실시간으로 수행한다.
Model
- REST 서버 내에서 동작하는 머신러닝 모델이다.
- 클라이언트 데이터를 처리하여 예측 결과를 생성한다.
장점
- 실시간 예측 결과 제공이 가능하다.
- 사용자 요청마다 최신 데이터를 기반으로 결과를 반환한다.
- 서버 부하를 분산하여 안정적인 서비스를 제공할 수 있다.
단점
- 요청이 많아질 경우 서버 리소스 소모가 커질 수 있다.
- 모델이 항상 로드된 상태여야 하므로 메모리와 성능 최적화가 중요하다.
예측 서버를 빠르게 출시하고 싶은 경우
또는, 예측 결과를 실시간으로 얻을 필요가 있는 경우 사용하면 좋다.
Web single 패턴을 기본으로 잡고 다른 패턴들로 적용하면 개발이 수월 할 것이다.
Synchronous(동기식) 패턴
동기식 패턴은 한 번에 하나의 작업을 처리하는 방식이다. 클라이언트는 서버에 요청을 보내고, 서버가 작업을 완료하여 응답을 반환할 때까지 기다린다. 다음 작업은 이전 작업이 완료된 후에 시작된다.
예를 들어
커피집에서 직원이 1명일 경우
한 손님이 주문을 하고 직원이 준비를 완료할 때까지 다음 손님은 기다려야 한다.
작업 준비 중에는 새로운 주문을 받지 못하는 경우를 말한다.
이러한 것이 동기식 패턴이다.
Synchronous 패턴의 핵심은
위에 설명한 Web Single 패턴을 동기적으로 서빙이 가능하다는 점이다.
기본적으로 대부분의 REST API 서버는 동기적으로 서빙 한다.
즉, 단일 스레드 또는 단일 프로세스로 처리한다.
Synchronous Serving 구조
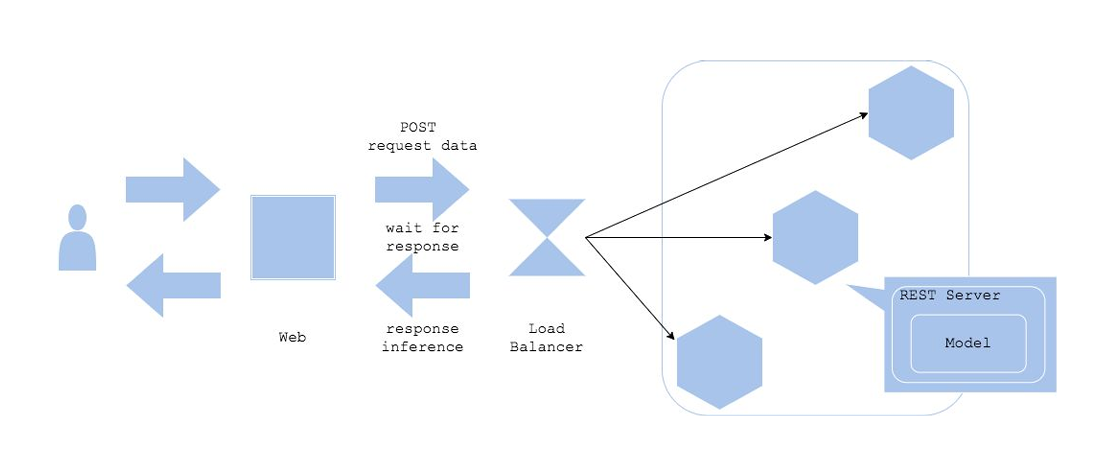
- Client (사용자)
- 사용자 또는 클라이언트가 시스템에 요청을 보낸다.
- 예: 웹 애플리케이션, 모바일 앱에서 데이터 분석 요청을 API로 보냄.
- Web
- 클라이언트 요청을 받아 서버로 전달하는 역할을 한다.
- POST 요청을 통해 데이터를 REST 서버에 전달.
- 클라이언트의 요청을 대기 상태로 유지하며, 응답이 오면 반환한다.
- Load Balancer (로드 밸런서)
- 여러 REST 서버로 요청을 분산 처리하여 서버 부하를 최소화.
- 요청량이 많아지더라도 서버의 안정성과 성능을 유지하도록 지원.
- REST Server
- 모델이 내장된 서버로, 요청 데이터를 받아 모델을 실행한다.
- 데이터를 처리한 뒤 예측 결과를 생성하여 클라이언트에 반환한다.
- Model
- REST 서버 내에서 동작하는 머신러닝 모델.
- 클라이언트가 요청한 데이터를 예측하거나 분석하는 핵심 역할을 담당.
- Response
- REST 서버에서 생성된 예측 결과를 클라이언트에 반환.
- 클라이언트는 이 응답을 기다리며 작업이 완료된 뒤 결과를 수신.
장점
아키텍처의 단순함 : 요청-응답 방식으로 설계가 직관적이고 복잡도가 낮다.
단순한 Workflow : 요청이 완료될 때까지 다른 작업을 수행할 필요가 없어 흐름이 명확하다.
단점
병목 현상:
- 요청이 많아질 경우 처리 시간이 길어질 수 있다.
- 예: 동시에 1000개의 요청이 들어오면 대기 시간이 길어지고, 일부 요청이 Drop되거나 Timeout 발생.
사용자 경험 악화:
- 예측 지연이 길어질 경우 사용자 불만이 증가할 수 있다.
- 빠른 응답이 중요한 서비스에서는 적합하지 않을 수 있다.
이러한 단점은 분업화
즉, 처리 속도를 높이기 위해 서버를 확장하고, 여러 작업을 병렬로 처리할 수 있도록 설계하면 된다.
커피집에 직원을 추가로 배치해 손님 응대를 분산하면 된다는 말
Asynchronous(비동기식) 패턴
비동기식 패턴은 하나의 작업을 시작한 뒤 결과를 기다리는 동안 다른 작업을 수행할 수 있는 방식이다.
작업이 완료되면 시스템이 결과를 알림으로써 처리 상태를 업데이트 한다.
예를 들어 음식점에서 진동벨을 사용하는 경우가 비동기식과 유사한 예이다. 손님이 주문 후 기다리지 않고 다른 일을 할 수 있다가, 진동벨이 울리면 음식을 가져가는 방식과 동일하다.
Asynchronous 의 핵심은
위에서 설명한 Web Single 패턴을 비동기적으로 서빙하는 것이다.
Asynchronous 구조
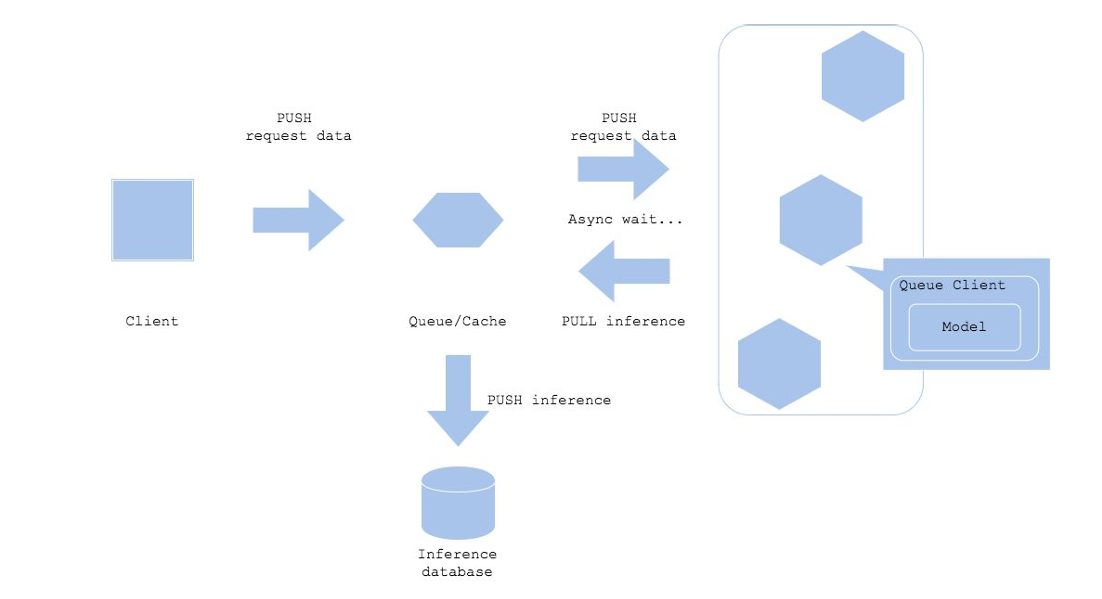
구조 설명
- Client (클라이언트)
- 클라이언트는 데이터를 요청(PUSH)하고, 결과를 기다리지 않고 다른 작업을 수행한다.
- 클라이언트는 작업이 완료되면 결과를 PULL하거나 알림을 통해 결과를 확인할 수 있다.
- Queue/Cache
- 요청 데이터를 관리하기 위한 대기열(Queue) 또는 캐시(Cache) 시스템이다.
- 클라이언트 요청을 받아서 모델이 처리할 때까지 대기 상태로 관리한다.
- 지하철 물품 보관소와 유사한 역할을 한다
- Model (모델)
- 대기열에서 데이터를 가져와(PULL) 예측 작업을 수행한다.
- 작업 결과를 다시 대기열이나 데이터베이스로 전달한다.
- Inference Database
- 모델이 생성한 예측 결과를 저장하는 데이터베이스이다.
- 클라이언트는 요청 결과를 직접 확인하거나 데이터베이스에서 결과를 조회한다.
- Async Wait
- 클라이언트는 결과가 즉시 반환되지 않으며, 비동기적으로 결과를 기다리거나 나중에 확인할 수 있다.
메세지 시스템을 추가해서 하는 것이다.
예시로 지하철 물품 보관소와 유사한 역할이다.
장점
- 클라이언트와 예측 프로세스의 분리
- 클라이언트와 서버의 관계가 독립적이어서 서로 의존적이지 않음.
- 클라이언트는 요청을 보내고 결과를 기다리지 않고 다른 작업을 진행할 수 있음.
- 클라이언트의 효율성 향상
- 요청 이후의 작업 흐름을 유지할 수 있어 사용자 경험(UX*이 개선됨.
- 서버 부하가 많아도 클라이언트가 즉시 영향을 받지 않음.
- 서버의 안정성
- 대량의 요청을 Queue에 저장하여 순차적으로 처리.
- 처리 속도를 제어하며 서버 과부하를 방지.
단점
- 메시지 Queue 시스템 필요:
- 별도의 Queue 관리 시스템(예: Redis, RabbitMQ)을 설계 및 구현해야 함.
- 대기열 관리와 메시지 전달 로직 추가로 구조가 복잡해짐.
- 실시간 예측에 부적합:
- Queue에서 메시지를 가져오고 처리하는 데 시간이 소요될 수 있음.
- 즉시 결과가 필요한 서비스에는 적합하지 않을 수 있음.
- 구현 난이도:
- 비동기 요청 및 응답 흐름 관리 로직 추가.
- 클라이언트가 결과를 어떻게 확인할지(알림, 조회 등) 설계 필요.
적합한 Use Case
- 클라이언트와 예측 프로세스의 의존성이 없는 경우
- 클라이언트가 요청 후 결과를 기다리지 않고도 진행 가능한 작업.
- 예: 대량 데이터 처리, 비동기 배치 작업.
- 결과를 즉시 받을 필요가 없는 경우
- 예측 결과가 바로 사용되지 않아도 되는 서비스.
- 예: 사용자 로그 데이터 분석, 추천 시스템에서 배치 예측.
- 클라이언트와 응답의 목적지가 분리된 경우
- 요청을 보내는 클라이언트와 결과를 사용하는 주체가 다를 때.
- 예: 데이터 분석 요청을 API로 보내고 결과를 다른 데이터베이스나 서비스가 활용.
이러한 패턴이 있다는 것을 알고 상황과 데이터에 맞는 패턴을 사용해야 한다.
무조건 어떤게 좋다는 답은 없기 때문에 종류를 인지하고
개발할때 참고해서 진행하자!
이상으로 Serving 패턴 종류에 대해서 알아보았습니다!
감사합니다.
끝
'딥러닝 (Deep Learning) > [07] - Serving' 카테고리의 다른 글
| Kubeflow 를 쉽게 이해하기 (피자 가게) (2) | 2025.01.31 |
|---|---|
| MLflow 란? (0) | 2025.01.31 |
| 딥러닝 파일 확장자의 차이점 *.mar, *.pt, *.pth, *.onnx (3) | 2024.12.19 |
| TorchServe 모델 배포 방법! (1) | 2024.12.19 |
| Model Serving 이란?? (3) | 2024.12.09 |