1. AlexNet 무엇인가?

120 만 개의 고해상도 이미지를 1000개의 서로 다른 클래스로 분류한
AlexNet은 인공지능의 ILSVRC에서 2012년에 당시 오차율 16.4%로 다른 모델 보다 압도적으로 우승한 모델입니다.
현재 시점에서 수치를 보면 그렇게 좋은 정확도가 아니지만, 대회 당시에는 굉장한 정확도였다고 합니다.
2011년에 우승했던 모델의 오차율이 25.8%였으니, 오차율 성능이 40% 만큼 좋아졌습니다.
AlexNet의 'Alex'는 모델 논문의 저자인 Alex Khrizevsky의 이름 입니다.
논문링크
https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
2. AlexNet 구조

AlexNet은 총 8개의 학습 가능한 레이어로 구성되어 있습니다.
이 중 5개는 합성곱(convolutional) 레이어이며, 나머지 3개는 완전 연결(fully connected) 레이어 로 구성.
1. 입력 이미지 (224x224x3)
- 256 x 256 x 3 다운 샘플링 후 중앙 크롭 (224x224x3)
- AlexNet은 224x224 크기의 RGB 이미지(3 채널)를 입력으로 input

2.1. 첫 번째 합성곱 레이어 (Conv1)
- 입력 크기: 224x224x3
- 필터 크기: 11x11
- 필터 수: 96 (96개의 서로 다른 패턴)
- 스트라이드: 4
- 출력 크기: 55x55x96
- 설명
첫 번째 합성곱 레이어는 11x11 크기의 필터를 사용하여 입력 이미지의 특징을 추출합니다.
스트라이드가 4이므로 필터가 4 픽셀씩 이동하면서 특징을 추출합니다.
결과적으로 96개의 특징 맵(feature map)이 생성됩니다.
2.2. 첫 번째 Max Pooling 및 LRN 레이어
- 입력크기 : 55x55x96
- 풀링 크기: 3x3
- 스트라이드: 2
- 출력 크기: 27x27x96
- 설명
첫 번째 합성곱 레이어의 출력을 받아 Max Pooling을 적용합니다.
풀링은 각 3x3 영역에서 최대값을 선택하여 특징 맵의 크기를 줄입니다.
그 후, Local Response Normalization(LRN)이 적용되어 신경망의 일반화를 돕습니다.

3.1. 두 번째 합성곱 레이어 (Conv2)
- 입력 크기: 27x27x96
- 필터 크기: 5x5
- 필터 수: 256
- 스트라이드: 1
- 출력 크기: 27x27x256 (패딩 사용해서 27x27 유지)
- 설명
두 번째 합성곱 레이어는 5x5 크기의 필터를 사용하여 이전 풀링 레이어의 출력을 더 깊게 분석합니다.
이 레이어에서는 256개의 특징 맵이 생성됩니다.
3.2 두 번째 Max Pooling 및 LRN 레이어
- 입력 크기: 27x27x256
- 풀링 크기: 3x3
- 스트라이드: 2
- 출력 크기: 13x13x256
- 설명
Conv2 레이어의 출력을 받아 두 번째 Max Pooling과 LRN이 적용됩니다.
이 과정은 특징 맵의 크기를 다시 줄이고, 특성 간의 상호작용을 정규화합니다.
256개의 이미지 피쳐를 생성

4.1 세 번째 합성곱 레이어 (Conv3)
- 입력 크기: 13x13x256
- 필터 크기: 3x3
- 필터 수: 384
- 스트라이드: 1
- 출력 크기: 13x13x384 (패딩 적용)
- 설명
세 번째 합성곱 레이어는 3x3 크기의 필터를 사용하여 더 복잡한 특징을 추출합니다.
이 레이어에서는 384개의 특징 맵이 생성됩니다.
4.2 네 번째 합성곱 레이어 (Conv4)
- 필터 크기: 3x3
- 필터 수: 384
- 스트라이드: 1
- 출력 크기: 13x13x384 (패딩 적용)
- 설명
네 번째 합성곱 레이어도 3x3 크기의 필터를 사용하지만,
이 레이어는 더 깊은 특징을 학습하기 위해 Conv3의 출력을 받아 384개의 특징 맵을 생성합니다.
4.3 다섯 번째 합성곱 레이어 (Conv5)
- 필터 크기: 3x3
- 필터 수: 256
- 스트라이드: 1
- 출력 크기: 13x13x256
- 설명
마지막 합성곱 레이어로, 이 레이어는 Conv4의 출력을 받아 256개의 특징 맵을 생성합니다.
4.4. 세 번째 Max Pooling 레이어
- 풀링 크기: 3x3
- 스트라이드: 2
- 출력 크기: 6x6x256
- 설명
다섯 번째 합성곱 레이어의 출력을 받아 마지막 Max Pooling을 적용하여 특징 맵의 크기를 줄이고,
완전 연결 레이어로 전달할 준비를 합니다.
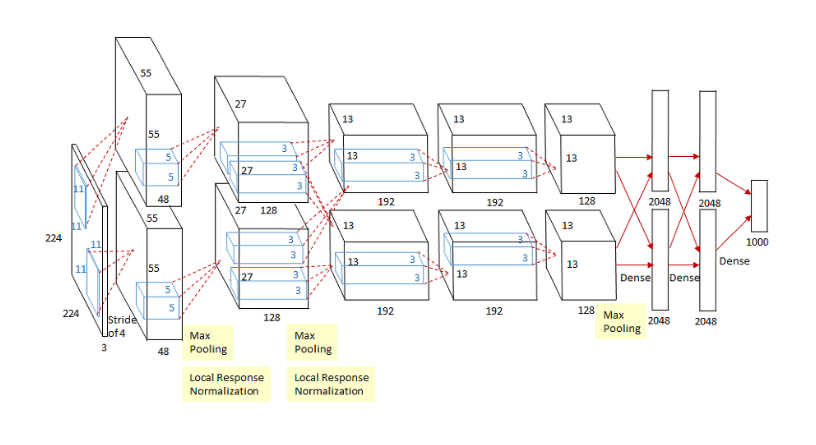
5.3. 첫 번째 완전 연결 레이어 (Dense1)
- 뉴런 수: 4096
- 설명
마지막 풀링 레이어의 출력을 1차원 벡터로 펼친 후,
4096개의 뉴런과 연결된 첫 번째 완전 연결 레이어로 전달합니다.
이 레이어에서는 ReLU 활성화 함수가 사용됩니다.
5.4 두 번째 완전 연결 레이어 (Dense2)
- 뉴런 수: 4096
- 설명
Dense1 레이어의 출력을 받아 동일하게 4096개의 뉴런과 연결된 두 번째 완전 연결 레이어로 전달합니다.
이 레이어 역시 ReLU 활성화 함수가 사용됩니다.
5.5 세 번째 완전 연결 레이어 (Dense3)
- 뉴런 수: 1000 (출력 클래스 수)
- 설명
마지막으로, Dense2 레이어의 출력을 받아 1000개의 클래스(ILSVRC의 클래스 수)에 대해 확률을 출력하는
소프트맥스(Softmax) 레이어와 연결됩니다. 이 레이어는 이미지가 특정 클래스에 속할 확률을 계산합니다.
3. AlexNet 의 특징
1. Relu 함수 사용

AlexNet의 특징은 ReLU 활성화 함수의 도입입니다.
이전에는 주로 sigmoid나 tanh 함수가 사용되었으나, ReLU는 계산 효율성과 학습 속도 면에서 큰 이점을 제공 했고,
기존의 Vanishing Gradient 문제를 해결 했고, 계산 효율성도 높였다.
실제 논문에서도 tahn 함수도 6배 높은 학습속도가 나왔다고 설명
2. GPU 가속
AlexNet은 두 개의 GPU를 사용하여 병렬 처리를 구현함으로써 대규모 데이터를 효율적으로 학습할 수 있었습니다.
이는 당시의 컴퓨터 하드웨어 한계를 극복하는 중요한 요소였습니다.
3. LPN (Local Response Normalization) 사용
AlexNet에서 처음 도입되었습니다.
LRN은 특정 뉴런의 활성화 값이 주변 뉴런들의 활성화 값과 상호작용하게 함으로써,
신경망이 더 잘 일반화되도록 도와줍니다.
이 기법은 특히 이미지 분류와 같은 작업에서 성능 향상에 기여 합니다.
LPN 의 효과
- 경쟁적인 억제
LRN은 비슷한 위치에서 강한 응답을 보이는 뉴런들 간에 경쟁을 유도합니다. 이렇게 하면 특정 뉴런이 지나치게 높은 값을 가지지 않도록 억제할 수 있습니다. 결과적으로, 다른 뉴런들이 더 많이 활성화될 수 있으며, 이는 네트워크가 더 다양한 특징을 학습하게 합니다. - 과적합 방지
LRN은 과적합을 방지하는 데 도움을 줄 수 있습니다. 과적합은 신경망이 훈련 데이터에 지나치게 특화되는 문제를 말하는데, LRN을 통해 출력이 정규화되면 네트워크가 특정 패턴에만 의존하지 않도록 할 수 있습니다. - ReLU와의 시너지
AlexNet에서 LRN은 ReLU 활성화 함수와 함께 사용되었습니다. ReLU는 비선형 활성화 함수로, 음수 값을 0으로 설정하고 양수 값만을 전달합니다. ReLU는 활성화를 유도할 수 있지만, LRN을 통해 이러한 활성화 값이 너무 커지지 않도록 조절할 수 있습니다.
근래의 CNN 계열에서 Batch Normalization과 같은 더 발전된 정규화 기법이 더 자주 사용
4. Overfiting 해결
AlexNet에는 6천만개의 parameters가 있습니다.
이미지 1000개 classes로 분류하기 위해서는 상당한 overfitting 없이 수 많은 parameters를 학습 시키는 것은 어렵다고 말합니다. AlexNet 논문에서는 overfitting을 해결하기 위해 적용한 두 가지 기법을 사용합니다.
첫번째는 Augmentation 이고, 두번째는 Dropout입니다.
- Data Augmentation
Augmentation은 CNN 모델에서 데이터를 다양하게 증대시키는 방법입니다.
데이터 증대는 두가지 방법을 사용하는데, 비교적 간단한 수학적 연산만을 필요로 하며
GPU나 CPU의 계산자원을 거의 소모하지 않고 데이터 증강 가능합니다.
첫번째는 단순 '수평반전'
두번째는 RGB 픽셀 값을 변화

쉽게 설명하면 1개의 이미지를 수평으로 뒤집고,
이를 랜덤으로 crop해서 이미지를 증대시키는 방법입니다.
이렇게 전환한다면 더 많은 학습 이미지를 형성하고 다양한 학습이 가능 합니다.
- Drop out
Dropout이란 말 그대로 네트워크의 일부를 생략하는 것 입니다.
아래 그림처럼 네트워크의 일부를 생략하고 학습을 진행하게 되면,
생략한 네트워크는 학습에 영향을 끼치기 않게 됩니다.

4. AlexNet의 영향
AlexNet의 성공 이후 VGG, GoogLeNet, ResNet 등과 같은 후속 모델들은
AlexNet의 구조를 기반으로 더 깊고 복잡한 신경망을 개발했습니다
- VGGNet
VGGNet은 AlexNet의 기본 구조를 더욱 깊게 만든 모델로,
더 작은 필터(3x3)를 사용하여 네트워크의 깊이를 증가시켰다.
이는 더 세밀한 특징을 학습하는 데 도움을 주었다.
- ResNet
ResNet은 "잔차 연결(residual connections)"을 도입하여 매우 깊은 신경망이 가지는 기울기 소실(vanishing gradient) 문제를 해결 했습니다. ResNet은 100개 이상의 레이어를 가지면서도 효과적으로 학습할 수 있음을 보여주었습니다.
5. AlexNet Test Code
import torch
import torch.nn as nn
import torchvision
from torchsummary import summary
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.feature_extraction = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11,
stride=4, padding=2, bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0),
nn.Conv2d(in_channels=96, out_channels=192,
kernel_size=5, stride=1, padding=2, bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0),
nn.Conv2d(in_channels=192, out_channels=384,
kernel_size=3, stride=1, padding=1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384, out_channels=256,
kernel_size=3, stride=1, padding=1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256,
kernel_size=3, stride=1, padding=1, bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0),
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(in_features=256*6*6, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Linear(in_features=4096, out_features=num_classes),
)
def forward(self, x):
x = self.feature_extraction(x)
x = x.view(x.size(0), 256*6*6) # 8, 9216
x = self.classifier(x)
return x
if __name__ == '__main__':
model = AlexNet()
alex = model.cuda()
summary(alex, (3, 224, 224))
결과

'딥러닝 (Deep Learning) > [05] - 논문 리뷰' 카테고리의 다른 글
| ResNet 논문 리뷰 (2) | 2024.09.20 |
|---|---|
| R-CNN 논문 리뷰 (2) | 2024.09.03 |
| 순환 신경망 (RNN) 이란? [4편] (1) | 2024.08.18 |
| 순환 신경망 (RNN) 이란? - BPTT [3편] (0) | 2022.03.13 |
| LSTM 이란? [2-1편] (0) | 2022.03.11 |