1. AlexNet 이란?
AlexNet은 인공지능의 ILSVRC에서 2012년에 당시 오차율 16.4%로 다른 모델 보다 압도적으로 우승한 모델입니다.
현재 시점에서 수치를 보면 그렇게 좋은 정확도가 아니지만, 대회 당시에는 굉장한 정확도였다고 합니다.
2011년에 우승했던 모델의 오차율이 25.8%였으니, 오차율 성능이 40% 만큼 좋아졌습니다.
AlexNet의 'Alex'는 모델 논문의 저자인 Alex Khrizevsky의 이름 입니다.
2. AlexNet 구조
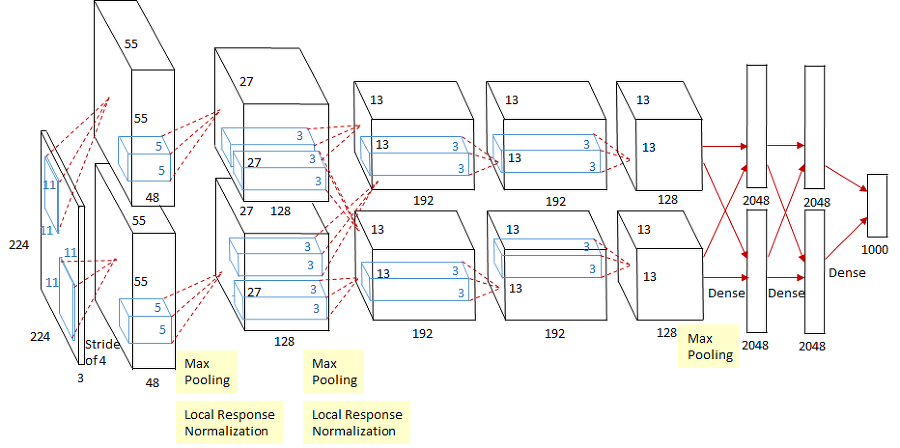
AlexNet은 위의 그림과 같은 구조 입니다.
순서대로 나열하면 아래와 같습니다.
- Input layer
- Conv1 - MaxPool1 - Norm1
- Conv2 - MaxPool2 - Norm2
- Conv3 - Conv4 - Conv5 - Maxpooling
- FC1- FC2
- Output layer
Input layer
224x224x3 크기의 이미지
Conv_1
11x11(stride=4, padding=0)의 Kernel (filter) 96개
Input : 224x224x3
Output : 55x55x96
MaxPooling_1
3x3(stride=2, padding=0) Kernel (filter)
Input : 55x55x96
Output: 27x27x96
Norm_1
LRN을 사용한 Normalization layer 이며, 자세한 내용은 아래에 있습니다.
Input : 27x27x96
Output : 27x27x96
Conv_2
5x5(Stride=1, Padding=2) Kernel(filter) 256개
Input : 27x27x96
Output : 27x27x256
MaxPooling_2
3x3(stride=2, padding=0) Kernel
input : 27x27x256
output : 13x13x256
Norm_2
LRN을 사용한 Normalization layer
Input : 13x13x256
Output : 13x13x256
Conv_3
3x3(Stride=1, Padding=1) Kernel(filter) 384개
Input : 13x13x256
Output : 13x13x384
Conv_4
3x3(Stride=1, Padding=1) Kernel(filter) 384개
Input : 13x13x384
Output : 13x13x256
Conv_5
3x3(Stride=1, Padding=1) Kernel(filter) 256개
Input : 13x13x384
Output : 13x13x256
MaxPooling_3
3x3(stride=2, padding=0) Kernel
Input : 13x13x256
Output : 6x6x256
FC_1
FCL 4096개
Input : 6x6x256
Output : 4096
FC_2
FCL 4096개
Input : 4096
Output : 4096
Output layer
FCL 1000 Softmax
Input : 4096
Output : 1000
3. AlexNet 특징
1. Relu 함수
활성화 함수로 Relu 함수를 사용 했습니다.
이전까지는 Tanh 함수를 사용 했는데, 두 함수의 차이섬은 어떤 것이 있을까요?
우선 두 함수의 생김새는 아래와 같습니다.

가장 큰 차이점은 tanh함수는 [-1, 1] 범위에서 존재하지만,
ReLU함수는 [0, ∞] 범위에 존재한다는 점 입니다.
이러한범위는 논문의 'Saturating(포화상태)' 개념과 관련이 있습니다.
tanh 함수가 saturating function이기 때문에 non saturating한 ReLU보다 훨씬 느리다는 것이
Alex net 논문의 주장입니다. 그러면 Saturating function이란 무엇일까요?
쉽게 생각하자면 -∞ 또는 +∞ 범위로 국한되지 않고 발산하는 함수를 non-saturating 함수라고 정의 합니다.
ReLU함수는 +∞ 범위로 계속 무한대로 나아가고 있기에 non-saturating 함수이고,
반면 tanh함수는 [-1, 1]의 범위로 되어있기 때문에 saturating 함수 입니다.
이러한 saturating 함수의 완만한 기울기는 Gradient의 Update를 느리게 만든다고 알려져 있습니다.

실제로 논문에서 제시한 위 그래프를 보시면,
실선인 ReLU 함수가 적은 epoch에도 빠른 Error rate 감소를 보이고 있습니다.
실제로 6배정도 더 빠른 성능을 보였다고 합니다.
따라서 Alexnet 에서는 Relu 활성화 함수를 채택 했습니다.
2. Local Responce Normalization(LRN) 의 사용
Batch normalization으로 잘 알려진 정규화 계열의 방법 입니다.
이 방법은 인체의 현상 중 lateral inhibition(측면억제)에서 영감을 받아 만들어졌습니다.
LRN은 일반화(generalizaion) 목적으로 사용 합니다.
위의 설명과 같이 ReLU는 non-saturating 함수이기 때문에 saturating을 예방하기 위한 입력 normalizaion이 필요로 하지 않는 성질을 갖고 있습니다. ReLU는 양수값을 받으면 그 값을 그대로 neuron에 전달하기 때문에 너무 큰 값이 전달되어 주변의 낮은 값이 neuron에 전달되는 것을 막을 수 있습니다. 이것을 예방하기 위한 normalization이 LRN 입니다.

위 그림은 측면 억제의 유명한 그림인 헤르만 격자입니다. 검은 사각형안에 흰색의 선이 지나가고 있습니다.
신기한 것은 흰색의 선에 집중하지 않을 때 회색 점이 보이는데 이러한 현상이 측면 억제에 의해 발생하는 것입니다.
이는 흰색으로 둘러싸인 측면에서 억제를 발생시키기 때문에 흰색이 더 반감되어 보입니다.
AlexNet에서 LRN을 구현한 수식을 살펴보겠습니다.

a는 x,y 위치에 적용된 i번째 Kernel의 Output을 의미하고
a를 normalization하여 큰 값이 주변의 약한 값에 영향을 주는 것을 최소화 했다고 합니다.
이러한 기법으로 top-1와 top-5 error를 각각 1.4%, 1.2% 감소시켰다고 합니다.
하지만 AlexNet 이후 현재 CNN에서는 LPR 대신 Batch normalization 기법이 많이 쓰입니다.
3. Overlapping Pooling
Pooling을 'Overlap(중첩)' 하여 사용한 것 입니다.
아래 그림은 기존방식과 중첩방식을 보여줍니다.

기존에는 위 그림의 상단처럼 Overlap 하지 않은 pooling을 사용했습니다.
하단 그림은 stride를 조절하여 Overlappling pooling을 사용했습니다.
이는 기존의 방법보다 약간 더 overfitting의 해결에 효과적이라는 점을 Error rates를 통해 알 수 있습니다.
3. Overfiting 해결
AlexNet에는 6천만개의 parameters가 있습니다.
이미지 1000개 classes로 분류하기 위해서는 상당한 overfitting 없이 수 많은 parameters를 학습 시키는 것은 어렵다고 말합니다.
AlexNet 논문에서는 overfitting을 해결하기 위해 적용한 두 가지 기법을 사용합니다.
첫번째는 Augmentation 이고, 두번째는 Dropout입니다.
1. Data Augmentation
Augmentation은 CNN 모델에서 데이터를 다양하게 증대시키는 방법입니다.
데이터 증대는 두가지 방법을 사용하는데,
첫번째는 단순 '수평반전'
두번째는 RGB 픽셀 값을 변화

쉽게 설명하면 1개의 이미지를 수평으로 뒤집고,
이를 랜덤으로 crop해서 이미지를 증대시키는 방법입니다.
이렇게 전환한다면 더 많은 학습 이미지를 형성하고 다양한 학습이 가능 합니다.
2. Drop out
Dropout이란 말 그대로 네트워크의 일부를 생략하는 것 입니다.
아래 그림처럼 네트워크의 일부를 생략하고 학습을 진행하게 되면,
생략한 네이트워크는 학습에 영향을 끼치기 않게 됩니다.

4. AlexNet 간단한 코드
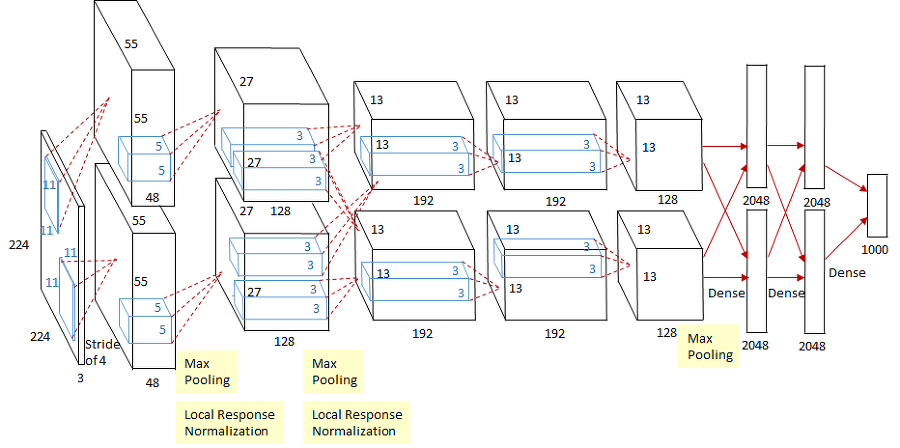
맨 처름 소개드렸던 AlexNet 구조 입니다.
아래 그림 구조에 따라서 구현되는 간단한 class 코드 입니다.
import torch
import torch.nn as nn
import torchvision
from torchsummary import summary
class AlexNet(nn.Module):
def __init__(self,num_classes=1000):
super(AlexNet,self).__init__()
self.feature_extraction = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=96,kernel_size=11,stride=4,padding=2,bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2,padding=0),
nn.Conv2d(in_channels=96,out_channels=192,kernel_size=5,stride=1,padding=2,bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2,padding=0),
nn.Conv2d(in_channels=192,out_channels=384,kernel_size=3,stride=1,padding=1,bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384,out_channels=256,kernel_size=3,stride=1,padding=1,bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,stride=1,padding=1,bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0),
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(in_features=256*6*6,out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Linear(in_features=4096, out_features=num_classes),
)
def forward(self, x):
x = self.feature_extraction(x)
x = x.view(x.size(0),256*6*6) # 8, 9216
x = self.classifier(x)
return x
if __name__ =='__main__':
model = AlexNet()
alex = model.cuda()
summary(alex, (3,224,224))
아래는 위의 코드 summary 출력 결과 입니다.

이상으로 AlexNet 리뷰를 마치겠습니다.
AlexNet 으로 학습하는 코드는 추후 업데이트 하겠습니다.
감사합니다.
출처
'AI > 딥러닝' 카테고리의 다른 글
| 순환 신경망 (RNN) 이란? [2편] (0) | 2022.03.11 |
|---|---|
| 순환 신경망 (RNN) 이란? [1편] (0) | 2022.03.11 |
| CNN의 구조 (LeNet - 5) (0) | 2022.02.24 |
| 2. 딥러닝은 학습을 어떻게 할까? (0) | 2022.02.20 |
| 1. 인공신경망 - ANN (Artifical Neural Network) 그리고 딥러닝 이란? (0) | 2022.02.20 |




댓글