FCN 의 한계점

1. 객체의 크기가 크거나 작은 경우 예측을 잘 하지 못하는 문제
FCN(Fully Convolutional Network)은 객체의 크기에 따라 예측 정확도가 달라지는 문제가 있다. 특히, 큰 객체의 경우 지역적인 정보만을 사용해 예측하기 때문에 오차가 발생하기 쉽다. 위의 이미지에 상당 부분을 보면, 버스의 앞 부분을 버스로 인식하지만 유리창에 비친 자전거를 보고 자전거로 예측하는 문제가 발생하기도 한다. 이는 동일한 객체여도 부분적으로 다른 레이블이 예측될 가능성을 높인다.
작은 객체의 경우 무시되는 문제도 존재한다. 작은 객체는 이미지 내에서 충분한 정보가 제공되지 않아 삭제되거나 아예 예측이 되지 않는 경우가 발생한다. 실제로 작은 객체의 일부가 있는 이미지에서도 FCN은 이를 무시하거나 다른 객체로 잘못 인식할 가능성이 크다. 이미지 하단 부분을 보면, 작은 부분을 잘못 예측하는 경우가 있다. 이는 작은 정보가 삭제되거나 무시될 수 있음을 의미한다.
2. 객체의 디테일한 모습이 사라지는 문제 발생
Deconvolution 절차가 단순하여 경계를 정확하게 학습하기 어렵다는 점 또한 FCN의 한계 중 하나이다. FCN 모델은 deconvolution을 사용해 특징을 복원하려 하지만, 이 과정이 단순하기 때문에 경계나 세부적인 형태를 학습하는 데 한계가 있다.
예를 들어, FCN-8s와 같은 구조에서는 sum 연산을 사용해 특징을 복원하지만, 이러한 단순한 연산은 복잡한 객체의 형태나 경계를 섬세하게 표현하기 어렵다. 아래 이미지를 보면, 객체의 디테일한 모양이 사라지며, 경계가 불명확해져 예측 품질이 좋지 않다고 볼 수 있다.

DeconvNet
DeconvNet은 객체의 위치와 형태를 더욱 정밀하게 예측하기 위해 설계된 구조이다.
이 네트워크는 FCN(Fully Convolutional Network)과 유사하지만, 추가적인 deconvolution 단계를 통해 upsampling을 수행하여 보다 높은 해상도로 예측을 가능하게 한다. 이는 작은 객체나 디테일한 부분도 잘 복원할 수 있는 장점을 가진다.
우선 아래 그림은 FCN 32s, 16s, 8s 구조를 보여준다.
자세한 설명은 아래 블로그 링크에서 보도록 하자.
FCN32s, FCN16s, FCN8s 이란?
FCN 이란?FCN은 2015년에 처음 소개된 신경망 모델로, 이미지의 픽셀 단위 예측을 수행하여 분할(Segmentation) 작업에서 중요한 역할을 하게 되었다. 이후 많은 연구에서 기본 모델로 사용되며 다양한
ai-bt.tistory.com

1. DeconvNet의 주요 특징
우선 DeconvNet과 FCN의 동일한 부분은 앞에 downsampling은 FCN과 동일하게 진행된다는 점이다. VGG16 기반의 Convolution Network 구조를 사용해 특징을 추출하고, 이를 통해 이미지의 저해상도 특징 맵을 만든다.
하지만 뒷부분의 upsampling 과정이 추가된 것이 DeconvNet의 특징이다. 이 과정에서는 Unpooling과 Deconvolution 단계를 통해 이미지 해상도를 점진적으로 복원하고, 더 정밀한 예측을 가능하게 한다. 이를 통해 FCN에서 부족했던 디테일한 부분이나 작은 객체의 예측을 보완하려는 구조적 개선이 이루어진다.

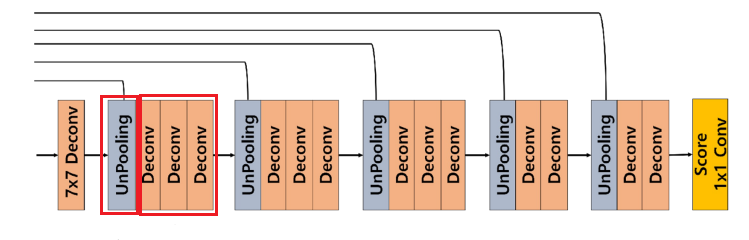
2. DeconvNet의 UpSampling 과정
DeconvNet에서 업샘플링은 Unpooling과 deconvolution(Transposed Convolution) 과정을 반복적으로 사용하여 이루어진다. 이 두 가지 과정을 통해 이미지의 해상도를 높이면서 더 정확한 디테일을 복원하려고 한다.
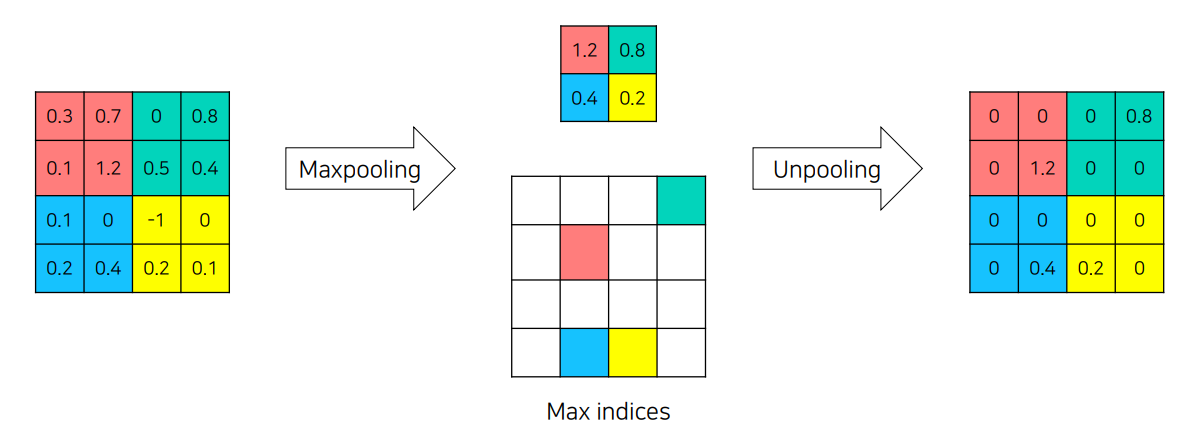
Unpooling
Unpooling은 입력 이미지의 풀링 단계에서 손실된 위치 정보를 복원하는 역할을 한다. 일반적인 풀링 과정에서는 픽셀의 위치 정보가 손실되기 때문에, 이를 다시 복원해주는 Unpooling을 통해 세부적인 경계 정보를 보존하고자 한다. 예를 들어, 풀링 과정에서 최대값이 있는 위치를 기억해두었다가, 업샘플링할 때 해당 위치에 다시 최대값을 채워 넣는 방식으로 디테일을 살린다. 아래의 이미지 처럼 위치의 정보를 기억한다고 생각하자.
Unpooling을 통해 경계를 복원할 수 있지만, 이로 인해 생기는 Sparse한 Activation Map을 채워줄 필요가 있다. 이러한 빈 부분을 채우는 작업은 Transposed Convolution이 담당하며, 이를 통해 전체적인 이미지를 좀 더 촘촘하게 복원하게 된다. Transposed Convolution은 Unpooling으로 인해 발생한 빈 공간에 정보를 추가해주고, 세밀한 디테일과 전반적인 윤곽을 재구성하는 역할을 한다.
Deconvolution (Transposed Convolution)
Unpooling이 위치 정보를 복원하는 데 중점을 두었다면, Transposed Convolution은 전체적인 모양을 복원하는 역할을 한다. 이를 통해 이미지의 세부적인 윤곽뿐만 아니라 전반적인 형상을 다시 만들어내는 데 도움이 된다.
DeconvNet에서는 이 두 가지 과정을 반복적으로 적용하여 작은 객체의 형태와 세밀한 경계를 복원하고, 고해상도의 예측을 가능하게 한다. FCN에서 부족했던 디테일 복원 능력을 개선하는 핵심 요소가 바로 이러한 Unpooling과 Transposed Convolution 과정이다.
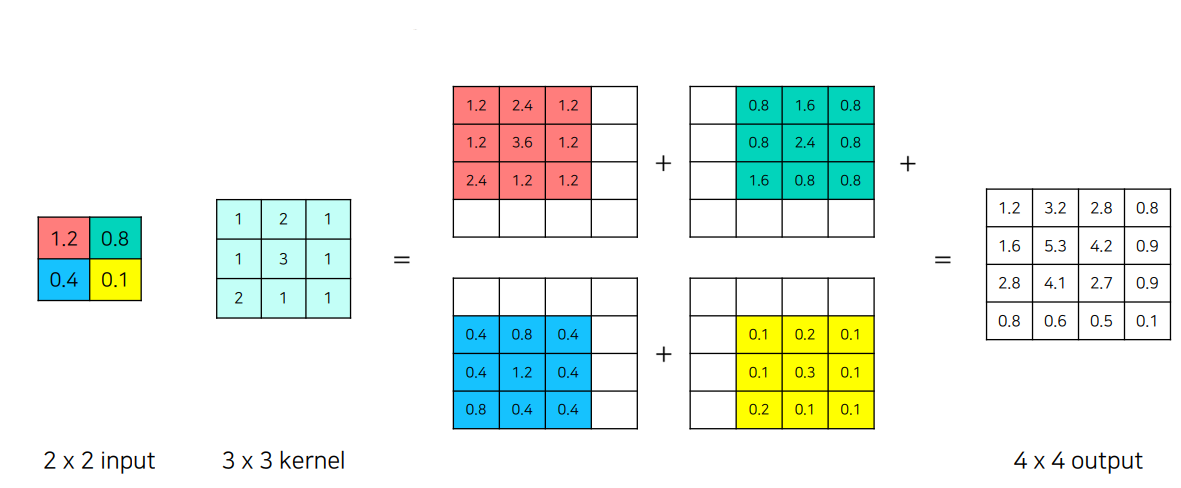
2x2 입력에 대해 3x3 커널을 적용하여 4x4 출력이 생성되는 것을 볼 수 있다. 각 값이 커널과 곱해져 큰 맵을 구성하며, 이로 인해 픽셀의 밀집도가 높아지고 세부적인 내용이 채워진다. Unpooling이 외곽의 모양을 유지하는 역할을 한다면, Deconvolution은 내부의 패턴과 세부 요소를 섬세하게 채워주는 역할을 한다고 볼 수 있다.
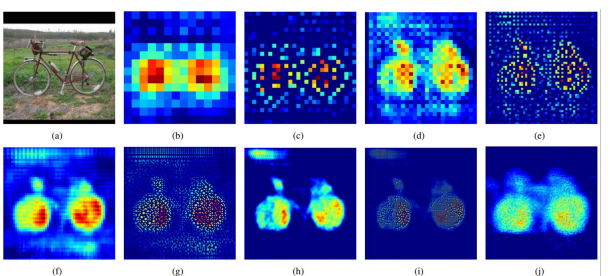
Transposed Convolution 단계 (b, d, f, h, j)
b, d, f, h, j 단계는 Transposed Convolution을 수행하여 특징 맵을 더욱 세밀하게 복원하는 단계이다. 이 과정은 단순히 크기를 키우는 것에 그치지 않고, 픽셀 간의 정보를 세밀하게 채워 넣어 객체의 구조를 더 명확하게 드러낸다. 이를 통해 초기에는 흐릿하게 보이던 객체의 윤곽이 점점 선명해지며, 전체적인 모양이 형성된다.
Unpooling 단계 (c, e, g, i)
나머지 단계들은 Unpooling을 통해 객체의 기본적인 형태를 복원하는 역할을 한다. Unpooling은 Pooling에서 손실된 위치 정보를 복원하여 전체적인 구조를 유지하게 한다. 이 과정은 빠르게 이미지의 크기를 확장하고 객체의 외곽선과 경계를 회복하는 데 주로 사용된다.
전체적인 복원 과정
이 두 가지 과정을 번갈아 수행함으로써, 네트워크는 객체의 큰 틀과 세부적인 모양을 점진적으로 복원해 나간다. Unpooling은 기본적인 외곽을 만들고, Transposed Convolution은 그 안을 세밀하게 채우는 방식으로 조합되어 보다 정확하고 고해상도의 이미지를 재구성하게 된다.
3. DeconvNet 아키텍쳐

import torch
import torch.nn as nn
# CBR (Convolution + BatchNorm + ReLU)
def CBR(in_channels, out_channels, kernel_size=3, stride=1, padding=1):
"""Convolution layer followed by BatchNorm and ReLU activation."""
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
# DCB (Deconvolution + BatchNorm + ReLU)
def DCB(in_channels, out_channels, kernel_size=3, stride=1, padding=1):
"""Deconvolution (Transposed Convolution) layer followed by BatchNorm and ReLU activation."""
return nn.Sequential(
nn.ConvTranspose2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
# DeconvNet Model
class DeconvNet(nn.Module):
def __init__(self, num_classes):
super(DeconvNet, self).__init__()
# Encoder (Convolutional Layers with Pooling)
# conv1 block
self.conv1_1 = CBR(3, 64, 3, 1, 1)
self.conv1_2 = CBR(64, 64, 3, 1, 1)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True)
# conv2 block
self.conv2_1 = CBR(64, 128, 3, 1, 1)
self.conv2_2 = CBR(128, 128, 3, 1, 1)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True)
# conv3 block
self.conv3_1 = CBR(128, 256, 3, 1, 1)
self.conv3_2 = CBR(256, 256, 3, 1, 1)
self.conv3_3 = CBR(256, 256, 3, 1, 1)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True)
# conv4 block
self.conv4_1 = CBR(256, 512, 3, 1, 1)
self.conv4_2 = CBR(512, 512, 3, 1, 1)
self.conv4_3 = CBR(512, 512, 3, 1, 1)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True)
# conv5 block
self.conv5_1 = CBR(512, 512, 3, 1, 1)
self.conv5_2 = CBR(512, 512, 3, 1, 1)
self.conv5_3 = CBR(512, 512, 3, 1, 1)
self.pool5 = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True, return_indices=True)
# Fully Connected Layers
self.fc6 = CBR(512, 4096, 7, 1, 0)
self.drop6 = nn.Dropout2d(0.5)
self.fc7 = CBR(4096, 4096, 1, 1, 0)
self.drop7 = nn.Dropout2d(0.5)
# Decoder (Deconvolutional Layers with Unpooling)
# fc6-deconv block
self.fc6_deconv = DCB(4096, 512, 7, 1, 0)
# unpool5 and deconv5 block
self.unpool5 = nn.MaxUnpool2d(2, stride=2)
self.deconv5_1 = DCB(512, 512, 3, 1, 1)
self.deconv5_2 = DCB(512, 512, 3, 1, 1)
self.deconv5_3 = DCB(512, 512, 3, 1, 1)
# unpool4 and deconv4 block
self.unpool4 = nn.MaxUnpool2d(2, stride=2)
self.deconv4_1 = DCB(512, 512, 3, 1, 1)
self.deconv4_2 = DCB(512, 512, 3, 1, 1)
self.deconv4_3 = DCB(512, 256, 3, 1, 1)
# unpool3 and deconv3 block
self.unpool3 = nn.MaxUnpool2d(2, stride=2)
self.deconv3_1 = DCB(256, 256, 3, 1, 1)
self.deconv3_2 = DCB(256, 256, 3, 1, 1)
self.deconv3_3 = DCB(256, 128, 3, 1, 1)
# unpool2 and deconv2 block
self.unpool2 = nn.MaxUnpool2d(2, stride=2)
self.deconv2_1 = DCB(128, 128, 3, 1, 1)
self.deconv2_2 = DCB(128, 64, 3, 1, 1)
# unpool1 and deconv1 block
self.unpool1 = nn.MaxUnpool2d(2, stride=2)
self.deconv1_1 = DCB(64, 64, 3, 1, 1)
self.deconv1_2 = DCB(64, 64, 3, 1, 1)
# Final Score layer to get class scores
self.score_fr = nn.Conv2d(64, num_classes, 1, 1, 0)
def forward(self, x):
# Encoding path with pooling indices
h = self.conv1_1(x)
h = self.conv1_2(h)
h, pool1_indices = self.pool1(h)
h = self.conv2_1(h)
h = self.conv2_2(h)
h, pool2_indices = self.pool2(h)
h = self.conv3_1(h)
h = self.conv3_2(h)
h = self.conv3_3(h)
h, pool3_indices = self.pool3(h)
h = self.conv4_1(h)
h = self.conv4_2(h)
h = self.conv4_3(h)
h, pool4_indices = self.pool4(h)
h = self.conv5_1(h)
h = self.conv5_2(h)
h = self.conv5_3(h)
h, pool5_indices = self.pool5(h)
# Fully Connected Layers
h = self.fc6(h)
h = self.drop6(h)
h = self.fc7(h)
h = self.drop7(h)
# Decoding path with unpooling using stored pooling indices
h = self.fc6_deconv(h)
h = self.unpool5(h, pool5_indices)
h = self.deconv5_1(h)
h = self.deconv5_2(h)
h = self.deconv5_3(h)
h = self.unpool4(h, pool4_indices)
h = self.deconv4_1(h)
h = self.deconv4_2(h)
h = self.deconv4_3(h)
h = self.unpool3(h, pool3_indices)
h = self.deconv3_1(h)
h = self.deconv3_2(h)
h = self.deconv3_3(h)
h = self.unpool2(h, pool2_indices)
h = self.deconv2_1(h)
h = self.deconv2_2(h)
h = self.unpool1(h, pool1_indices)
h = self.deconv1_1(h)
h = self.deconv1_2(h)
# Final classification layer
output = self.score_fr(h)
return output
끝. 이상입니다.
감사합니다!
'딥러닝 (Deep Learning) > [05] - 논문 리뷰' 카테고리의 다른 글
| [04] - FC DenseNet 이란? (0) | 2024.11.15 |
|---|---|
| [03] - 빠르면서도 정확한 SegNet (0) | 2024.11.14 |
| [01] - FCN32s, FCN16s, FCN8s 이란? (0) | 2024.11.12 |
| U-Net 의 이해 (10) | 2024.11.10 |
| Faster R-CNN (6) | 2024.10.04 |