데이터 중심 AI(Data-Centric AI)란?
데이터 중심 AI(Data-Centric AI)는 인공지능 성능 향상의 핵심이 모델이 아닌 데이터의 품질에 있다는 철학에서 출발한 접근 방식입니다. 기존에는 복잡하고 정교한 모델을 개발하는 것이 AI 성능 향상의 주된 방법이었다면, 데이터 중심 AI는 모델의 복잡성을 높이는 대신, 데이터 자체를 정제하고 개선하는 데 중점을 둡니다.
데이터 중심 AI에서는 고품질의 데이터를 통해 더 정확하고 신뢰할 수 있는 예측을 만들 수 있다는 점에 주목합니다. 따라서 데이터 라벨링의 일관성, 노이즈 제거, 데이터 증강, 데이터의 다양성 보장 등 데이터 자체를 개선하는 작업이 매우 중요합니다. 이 방법은 특히 작은 데이터셋이나 편향된 데이터로 인해 AI 모델이 한계를 보일 때 더 효과적입니다.
데이터 중심 AI의 장점은 모델을 자주 바꾸지 않고도 데이터의 품질만으로도 큰 성능 향상을 기대할 수 있다는 점입니다. 기업이나 연구자들이 모델 성능을 개선할 때 지나치게 복잡한 알고리즘에 의존하기보다, 데이터를 개선함으로써 효율적인 성능 개선을 이룰 수 있습니다.
Data-Centric AI 등장 배경
1. AI System 구성
AI System = Code + Data
AI 시스템은 Code(모델)와 Data로 구성됩니다. 우리는 종종 모델의 복잡도나 최적화 기술에 집중하곤 합니다. 하지만 많은 AI 프로젝트에서 실제로 더 많은 시간이 투자되는 부분은 데이터 준비입니다. 데이터를 정제하고, 라벨을 수정하고, 증강하는 작업들이 AI 성능에 미치는 영향은 매우 큽니다.
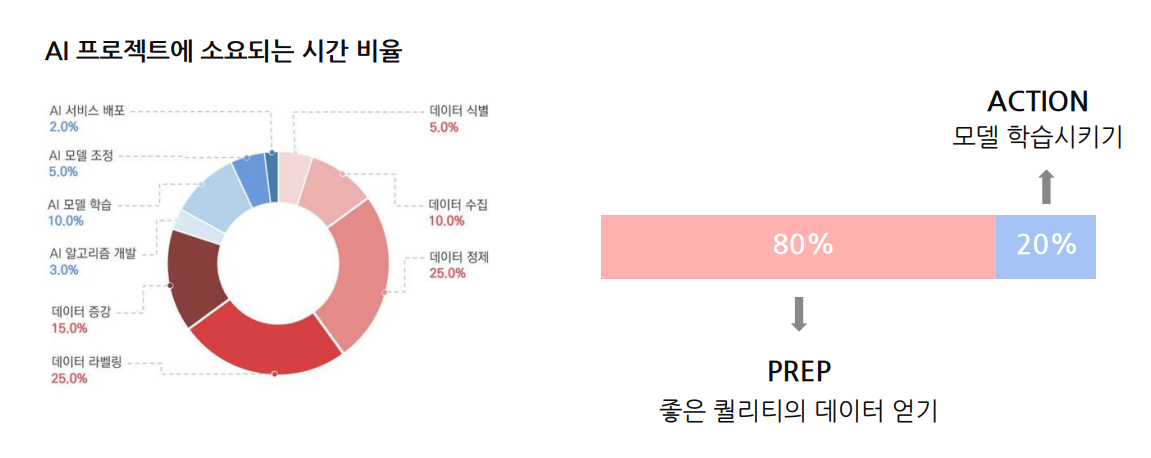
예를 들어, AI 프로젝트에서 소요되는 시간 비율을 보면, 데이터 작업이 전체의 80%를 차지하는 반면, 모델 학습에 사용하는 시간은 약 20%에 불과합니다. 이는 데이터의 중요성을 명확히 보여줍니다.
물론 전체 프로젝트가 다 그렇다는 것은 아니지만, 일반적인 경향을 말하는 것이다.
2. 모델 중심 AI와 데이터 중심 AI의 차이
AI 시스템을 개발할 때, 우리는 보통 모델의 성능을 개선하는 데 많은 시간을 투자하곤 합니다. 즉, 모델 중심 AI에서는 어떤 알고리즘을 사용할지, 어떤 하이퍼파라미터를 조정할지에 대해 고민합니다. 모델의 구조와 복잡성을 높여 더 나은 성능을 얻으려는 노력이 여기에 포함됩니다.
하지만 최근 AI 기술의 발전에 따라, 단순히 모델을 개선하는 것만으로는 충분하지 않다는 인식이 확산되고 있습니다. AI의 성능은 데이터에 크게 의존하기 때문입니다.

위 이미지를 보면 두 접근법의 차이를 직관적으로 알 수 있습니다.
- 모델 중심 AI(Model-Centric AI)에서는 데이터는 주어진 그대로 사용되고, 모델에 중점을 두어 성능을 높이려 합니다. 여기서 모델의 복잡성을 늘리거나 새로운 아키텍처를 도입하여 더 나은 결과를 얻고자 하는 것이 특징입니다.
- 반면, 데이터 중심 AI(Data-Centric AI)는 데이터의 품질을 향상시키는 데 초점을 맞춥니다. 즉, 좋은 데이터란 무엇인지를 파악하고, 학습 데이터와 평가 데이터를 모두 개선하여 성능을 극대화하려는 것입니다. 이는 데이터를 더 정제하고 라벨링을 개선하며, 데이터의 다양성을 보장하는 등 데이터 자체에 대한 관리와 품질 향상을 목표로 합니다.
3. Data-Centric AI의 정의와 접근 방법
Data-Centric AI는 성능을 개선하기 위해 모델(알고리즘)보다는 데이터 자체의 품질을 중점적으로 개선하는 접근 방식입니다. 즉, 모델을 고정한 상태에서 데이터를 어떻게 더 잘 관리하고 활용할 것인지 고민하는 것입니다.
1) 성능 향상을 위한 데이터 관점에서 고민
데이터 중심 AI의 핵심은 Hold the Code, Fix the Algorithm입니다. 즉, 모델이나 알고리즘은 그대로 두고, 데이터의 질을 높여 성능을 개선합니다. 여기에는 여러 가지 방법이 포함됩니다:
- 데이터 관리(Data Management): 새로운 데이터를 수집하고, 데이터의 일관성을 유지
- 데이터 증강(Data Augmentation): 데이터를 다양하게 변형하여 모델이 다양한 상황을 학습
- 데이터 필터링(Data Filtering): 노이즈나 오류가 있는 데이터를 필터링하여 성능을 높임.
- 합성 데이터(Synthetic Data): 실제 데이터를 대신할 수 있는 가상의 데이터를 생성해 데이터 부족 문제를 해결
- 라벨 일관성(Label Consistency): 라벨링의 정확성과 일관성을 유지하여 신뢰성 있는 학습 데이터를 제공
2) 모델을 바꾸지 않고 성능을 향상시킬 수 있을까?
모델 자체를 수정하지 않고도 데이터를 개선하면 성능을 높일 수 있습니다. 그렇다면 다른 모델을 찾아야 할까요? 데이터 중심 AI에서는 데이터를 이해하고, 이를 기반으로 모델을 개선할 수 있는 방법을 고민합니다.
- 데이터 품질 관리(Data Quality Control): 데이터를 더 잘 관리하고, 불필요한 데이터를 제거함으로써 성능을 개선
- 데이터 증강 및 합성 데이터 활용: 기존 데이터의 부족함을 해결하거나 데이터셋을 생성하여 모델의 성능을 향상
- AI 알고리즘과 데이터의 상호 작용: 데이터를 이해하는 AI 알고리즘을 사용해 모델을 개선할 수 있습니다. 예를 들어, 커리큘럼 러닝(Curriculum Learning)이나 액티브 러닝(Active Learning)과 같은 방법을 통해 학습 과정을 최적화할 수 있습니다.
3) 데이터 중심 평가(Data-Centric Evaluation)
데이터 중심 AI에서는 모델 자체가 아니라 모델이 데이터를 어떻게 다루는지를 평가하는 것이 중요합니다. 이를 위해 데이터 품질 측정 및 평가 지표 개발을 통해, 모델이 아닌 데이터에 대한 평가를 수행합니다. 즉, 데이터 품질의 변화가 모델 성능에 미치는 영향을 측정하고 관리하는 것이 핵심입니다.
Data Centric 중요성
1. AI 모델 서비스 과정
중요성을 살펴보기 전에,
우선 AI 모델 개발 및 서비스과정을 살펴보자.

위의 이미지처럼 보통의 AI 모델 서비스 개발과정 입니다.
모델 요구사항 확정 -> 데이터셋 준비 -> 모델 학습 및 디버깅 -> 설치 및 유지보수
이렇게 개발 후 모델 성능을 유지하고 향상시키는 방법이 무엇일까??
2. Data-Centric vs. Model-Centric
이 과정에서 가장 중요한 점은, 모델의 성능을 지속적으로 유지하고 개선하는 방법입니다.
이를 위해 두 가지 접근 방식이 존재합니다.

- Data-Centric Approach: 데이터의 품질을 지속적으로 관리하고 개선함으로써, 모델의 성능을 향상시키는 방법입니다. 데이터 수집, 라벨링의 일관성 유지, 데이터 증강 등 데이터와 관련된 모든 과정을 최적화하여 모델 성능을 높입니다. 특히, 데이터를 고도화하는 것만으로도 복잡한 모델 없이도 뛰어난 성능을 기대할 수 있다.
- Model-Centric Approach: 데이터는 고정된 상태에서 모델을 개선하는 방법이다. 더 복잡한 알고리즘을 도입하거나 모델의 구조를 개선하여 성능을 높이려는 시도이다. 기존의 AI 개발에서는 이 방식에 주로 의존했으나, 더 이상 모든 상황에서 효과적이지 않다는 점이 밝혀졌다.
2개의 방법이 있는데, 모델 성능 달성에 있어서 데이터와 모델에 대한 비중은 어떨까??

프로젝트마다 다를 수 있지만,
보편적으로 데이터, 모델 둘 다 같은 비중으로 중요하다고 말할 수 있다.
그렇다면 사용(서비스) 중인 모델 성능 개선시 데이터와 모델에 대한 비중은 어떻게 될까?

이미 운영 중인 AI 서비스를 개선하거나 성능을 높이려 할 때, 데이터의 비중이 매우 중요하다. 모델을 변경하여 성능을 개선하는 것도 한 방법이지만, 실제로는 데이터 관점에서 접근하는 것이 더 효율적인 경우가 많다.
왜 데이터를 통한 성능 개선이 더 나을까?
모델을 변경하는 경우, 검증, 재학습, 배포 등의 과정에서 많은 비용과 시간이 소요된다. 또한 새로운 모델을 도입하는 과정에서 예상치 못한 문제들이 발생할 수 있다. 반면, 데이터를 추가하거나 개선하는 것은 상대적으로 더 적은 리소스를 투입하면서도 성능을 크게 향상시킬 수 있는 방법이다.
결국, AI 서비스의 성능을 높이기 위해 데이터 중심 접근법을 사용하는 것이 더 효과적이고 경제적일 때가 많다. 데이터의 품질을 개선함으로써, 복잡한 모델을 변경하지 않고도 높은 정확도와 성능을 달성할 수 있는 가능성을 극대화할 수 있다.
Data-Centric AI 동향
1. Data Flaywheel
Data-Flywheel은 AI 시스템의 성능을 지속적으로 향상시키기 위한 데이터 중심의 순환 구조를 의미한다. 이 개념은 데이터 수집부터 모델 개발, 결과 분석, 재학습까지 이어지는 자동화된 데이터-모델 개선 사이클을 강조하고 있다.

Data-Flywheel은 AI 시스템의 성능을 지속적으로 개선하기 위한 데이터 중심의 순환 구조를 보여주고 있다. 데이터 수집, 주석화, 모델 개발, 결과 분석을 자동화하고 반복함으로써, AI 모델의 성능을 점진적으로 향상시킬 수 있는 방법론이다.
2. 라벨링의 중요성과 데이터 품질의 역할
AI 시스템에서 성능을 결정짓는 중요한 요소 중 하나는 라벨링과 데이터의 품질이다. 그러나, 많은 양의 라벨링 작업이 반드시 좋은 성능으로 이어지는 것은 아니며, 데이터의 질 역시 양만큼이나 중요하다. 이에 따라 데이터 중심 AI 접근법에서 라벨링의 정확성과 고품질 데이터의 중요성이 점점 더 강조되고 있다.
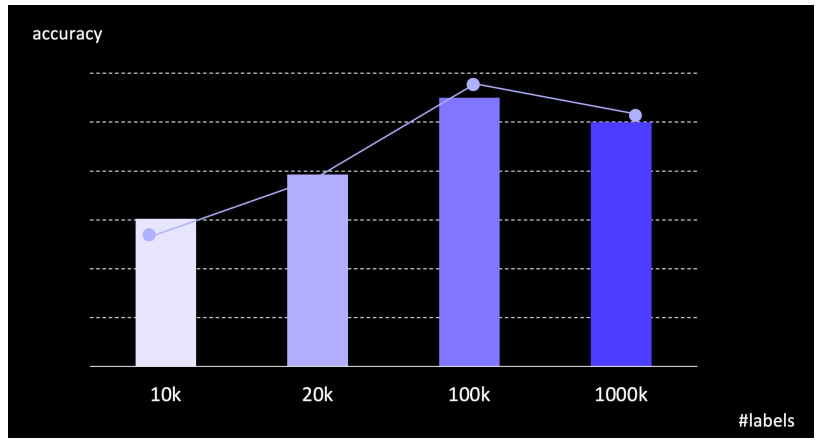
라벨링 작업에 대한 명확한 정답이 없고 비용이 크다.
위의 그래프에서 볼 수 있듯이, 라벨링된 이미지의 양이 많다고 해서 무조건 성능이 향상되는 것은 아니다. 10K, 20K, 100K로 라벨링 양이 증가할수록 성능이 올라가지만, 특정 시점 이후에는 오히려 성능이 감소할 수도 있다. 이는 단순히 라벨링의 양이 아닌, 라벨링의 질에 따라 성능이 결정될 수 있다는 점을 의미한다.
라벨링 작업은 또한 비용이 많이 들며, 정확하게 수행되지 않으면 오히려 모델 성능을 저해할 수 있다. 따라서 AI 성능을 높이기 위해서는 양질의 라벨링을 보장해야 하며, 이를 위해 많은 리소스가 필요하다.
3. 고품질 데이터와 데이터 균형의 중요성
AI 모델을 효과적으로 학습시키기 위해서는 단순히 데이터의 양만 고려할 것이 아니라, 데이터의 질과 균형을 함께 고민해야 한다. 데이터 중심 AI에서는 이러한 요소들이 모델 성능에 큰 영향을 미치며, 이는 특히 라벨링의 정확성과 데이터 분포에서 명확하게 나타난다.

고품질 데이터가 중요한 이유 (데이터의 양 < 데이터의 질)
고품질 데이터는 데이터의 양보다 더 중요한 역할을 한다. 그래프에서 볼 수 있듯이, 데이터가 많더라도 라벨이 노이즈가 많거나 불명확하면 성능이 오히려 낮을 수 있다. 반면, 정확한 라벨이 달린 데이터는 데이터 양이 적더라도 모델 성능을 더 크게 향상시킬 수 있다.
- Small data / Noisy labels: 데이터가 적고 라벨이 불명확한 경우, 모델 성능이 매우 낮다.
- Big data / Noisy labels: 데이터가 많더라도 라벨의 품질이 낮다면, 성능 개선에 한계가 있다.
- Small data / Clean labels: 데이터 양이 적어도 라벨이 정확하다면, 모델 성능이 크게 개선된다.
따라서, AI 성능을 높이기 위해서는 단순히 데이터의 양을 늘리는 것이 아닌, 양질의 데이터를 확보하는 것이 중요하다.
또한, 데이터의 균형이 맞아야 한다.

데이터의 균형은 모델 성능에 중요한 역할을 한다. 즉, 데이터가 특정 클래스에 편향되지 않고 골고루 분포되어 있어야 한다는 뜻이다. 예를 들어, 소량의 데이터라도 라벨이 정확하고 데이터 분포가 균일하다면, 모델 성능이 높아질 수 있다. 반면, 데이터가 불균형한 상태에서는 성능 향상에 어려움을 겪을 수 있다.
- Small data / Clean labels / Data imbalance: 데이터가 적고 라벨은 정확하지만, 특정 클래스에 편향된 경우 성능이 떨어질 수 있다.
- Small data / Clean labels / Data balance: 데이터가 적더라도 균형이 맞는 데이터를 사용하면, 성능을 높일 수 있다.
모든 AI 모델에서 데이터의 균형을 맞추는 것은 필수적인 작업이다. 특히, 데이터의 양이 적을수록 불균형 데이터는 성능에 큰 악영향을 미칠 수 있으므로 이를 보완하는 것이 중요하다.
데이터 중심 AI(Data-Centric AI)는 AI 성능을 향상시키기 위해 모델이 아닌 데이터의 품질과 균형에 중점을 둔다. 많은 양의 데이터가 있더라도, 라벨이 정확하지 않거나 데이터가 불균형하면 성능 개선에 한계가 있다. 반면, 정확한 라벨링과 고품질 데이터는 적은 양의 데이터로도 모델 성능을 크게 향상시킬 수 있다. 또한, 데이터의 균형이 맞지 않으면 특정 클래스에 편향된 결과를 초래할 수 있어, 데이터를 골고루 분포시키는 것이 중요하다. AI 모델의 지속적인 개선을 위해서는 데이터를 수집하고 주석화하는 데이터 플라이휠과 같은 반복적인 개선 사이클이 필요하다. 결국, 데이터의 질과 균형을 유지하는 것이 AI 성능을 극대화하는 핵심이며, 복잡한 모델 개선보다 효율적인 성능 향상 방법이 될 수 있다.
끝.
감사합니다.
'AI Naver boost camp > [Wekk 09] Data Centric' 카테고리의 다른 글
| [05] - OCR 의 데이터 포맷 UFO (3) | 2024.10.30 |
|---|---|
| [04] - OCR 기반 문서 이해 (2) | 2024.10.30 |
| [02] - OCR Tasks (8) | 2024.10.30 |



댓글