딥러닝 모델을 경량화하고 효율성을 높이기 위한 Pruning은 다양한 방법으로 적용될 수 있다.
Pruning은 크게 4가지 관점으로 나누어 분류할 수 있다.
Structure, Scoring, Scheduling, Initialization 각 관점에 대해 자세히 살펴보자.
Structure

Structure Pruning은 Pruning 단위의 세분화(granularity) 수준에 따라 Unstructured Pruning과 Structured Pruning으로 나뉜다. 각 방법은 프루닝 대상이 되는 단위와 모델 구조에 미치는 영향을 기준으로 구분된다.
1. Unstructured Pruning
Unstructured Pruning은 개별 파라미터(가중치)를 단위로 하여 Pruning을 수행하는 방식이다.
모델 내에서 특정 가중치가 중요하지 않다고 판단되면, 해당 값을 0으로 설정해 제거한다.
이 방식은 가중치 하나하나에 집중하여 불필요한 값을 제거하므로, 모델의 구조는 변경되지 않는다.
예를 들어, 특정 가중치가 0.03과 같이 작고 중요도가 낮다고 판단되면, 이를 0으로 설정한다.
이렇게 하면 모델의 전체 크기는 줄어들지만, 뉴런과 레이어는 그대로 남아 있기 때문에 모델의 구조는 유지된다.
Unstructured Pruning의 주요 특징은 Sparse Matrix을 만들어낸다는 점이다.
즉, 가중치 값들 중 대부분이 0으로 채워지며, 나머지 중요한 가중치들만 남게 된다. 하지만, Sparse Matrix(희소 행렬)을 다루기 위한 하드웨어나 소프트웨어의 최적화가 이루어지지 않은 경우, 계산 효율성이 제한적일 수 있다.
Unstructured Pruning은 매우 세밀한 단위로 파라미터를 조정할 수 있다는 점에서 장점이 있다. 그러나 모델 구조가 그대로 유지되기 때문에, 경량화된 모델이 하드웨어에서 반드시 빠르게 동작한다고 보장할 수는 없다.
간단한 요약
- 개별 파라미터(가중치)를 단위로 Purning을 수행한다.
- 특정 가중치가 중요하지 않다고 판단되면, 이를 0으로 변경한다.
- 모델의 구조는 변경되지 않는다.
2. Structured Pruning
Structured Pruning은 모델의 뉴런, 채널, 또는 레이어와 같은 구조적 단위를 기준으로 Pruning을 수행한다.
이 방식은 단순히 가중치를 0으로 설정하는 것이 아니라, 특정 뉴런이나 채널, 혹은 레이어 전체를 제거한다. 따라서 모델의 구조가 변경되며, 전체 네트워크가 더 단순화된다.
예를 들어, 특정 레이어 내에서 중요하지 않은 뉴런이 있다고 판단되면, 해당 뉴런과 관련된 모든 가중치를 함께 제거한다.
이렇게 하면 모델 구조 자체가 간소화되며, 계산량이 크게 줄어든다. Structured Pruning은 하드웨어에 친화적인 경량화를 이루는 데 매우 효과적이다.
특히, 임베디드 환경이나 실시간 응답이 요구되는 상황에서 Structured Pruning은 모델의 크기를 줄이고 계산 효율성을 극대화하는 데 유리하다. 하지만, Unstructured Pruning처럼 세밀한 조정을 하기에는 다소 제약이 있다.
간단한 요약
- 레이어 단위나 채널 단위 등, 구조적인 단위로 Pruning을 수행한다.
- 특정 뉴런, 필터, 채널, 레이어와 같은 구조적 단위를 통째로 제거한다.
- 모델의 구조가 변경된다.
Scoring
Scoring은 Pruning을 수행할 때, 어떤 파라미터를 제거할지 중요도를 계산하여 선정하는 과정이다.
모델 내에서 중요도가 낮은 파라미터를 제거함으로써, 성능에 큰 영향을 미치지 않으면서도 모델을 경량화할 수 있다.
1. 중요도를 계산하는 방법
1) 파라미터별 절댓값을 기준으로 평가

- 파라미터(가중치)의 절댓값이 작을수록 중요도가 낮다고 간주한다.
- 예: 절댓값이 0에 가까운 가중치들은 모델 성능에 미치는 영향이 작기 때문에 제거 대상이 된다.
2) 레이어별 -norm 사용

- 레이어의 전체 가중치를 -norm으로 계산하여, 특정 레이어의 중요도를 평가한다.
- -norm: 가중치의 절댓값 합.
- -norm: 가중치의 제곱합.
- 레이어의 -norm 값이 작을수록, 해당 레이어의 중요도가 낮아 제거 대상으로 고려된다.
2. 계산된 중요도를 반영하는 단위
중요도 점수를 기반으로, Pruning을 적용할 범위와 단위를 결정한다.
2가지 기법이 있다. Global, Local

1) Global Pruning
- 모델 전체에서 중요도를 계산하여, 중요도가 낮은 파라미터를 전역적으로 제거한다.
- 레이어 간에 가중치 중요도를 비교하므로, 모델 전체를 최적화하는 데 적합하다.
2) Local Pruning
- 각 레이어 내에서만 중요도를 계산하여, 레이어 단위로 파라미터를 제거한다.
- 각 레이어가 고유한 중요도를 가지며, 특정 레이어의 손실을 최소화할 수 있다.
간단히 말하면
레이어를 기반으로 한다고 했을때,
전체에서 50% 를 하느냐
각 레이어에서 50% 를 하느냐
차이가 있다.

Scoring은 Pruning은 대상을 선정하기 위한 핵심 과정이다.
파라미터나 레이어의 중요도를 평가하고, 이를 기반으로 제거할 대상을 결정함으로써, 성능을 유지하면서도 모델을 효과적으로 경량화할 수 있다. Global Pruning과 Local Pruning은 서로 보완적인 방식으로, 모델의 특성과 요구에 맞게 선택해야 한다.
Scheduling
Pruning 을 진행할 때, 한 번에 모든 파라미터를 제거할지, 아니면 여러 단계에 나누어 점진적으로 진행할지를 결정하는 것이 Scheduling이다. Scheduling은 Pruning 후 성능 손실을 얼마나 효과적으로 복구할 수 있느냐에 따라 모델 경량화의 성공 여부를 크게 좌우한다. 크게 One-shot Pruning과 Recursive Pruning 두 가지 방식으로 나눌 수 있다.
1. One-shot Pruning
One-shot Pruning은 한 번의 프루닝으로 많은 파라미터를 제거하고, 이후 Fine-tuning을 통해 모델의 성능을 복구하는 방식이다. 이 방식은 단순하고 빠르게 모델을 경량화할 수 있다는 장점이 있다. 그러나 한 번에 많은 파라미터를 제거하면 모델의 구조에 큰 변화를 초래하기 때문에, 성능이 크게 손실될 위험이 있다. 예를 들어, 모델의 파라미터를 한 번에 30% 제거한 후 Fine-tuning을 수행하여 성능을 복구하는 식으로 진행된다. 이런 방식은 시간적 제약이 있거나 간단한 경량화 작업을 요구하는 상황에서 유용하다.
예시
- 모델의 파라미터를 30% 한 번에 제거하고, 이후 Fine-tuning을 진행한다.
2. Recursive Pruning
Recursive Pruning은 Pruning 을 여러 단계에 나누어 점진적으로 진행하는 방식이다. 한 번에 적은 비율로 파라미터를 제거하고, 각 단계에서 Fine-tuning을 수행하여 성능을 복구한다. 이렇게 단계를 나누어 진행하면, 한 번에 많은 파라미터를 제거할 때 발생할 수 있는 성능 손실을 최소화할 수 있다. 또한, 모델의 안정성을 유지하면서 경량화를 달성할 수 있다는 장점이 있다.
예시:
- 첫 번째 단계에서 파라미터를 10% 제거하고 Fine-tuning을 수행.
- 두 번째 단계에서 추가로 10% 제거하고 다시 Fine-tuning을 수행.
- 이 과정을 반복하여 목표 프루닝 비율에 도달한다.

2개의 성능 비교을 비교해보면,
One-shot Pruning은 Pruning 비율이 낮을 때는 성능 손실이 크지 않지만, 비율이 높아질수록 성능이 급격히 하락한다.
반면 Recursive Pruning은 Pruning 비율이 높아도 성능이 상대적으로 안정적이다.
이는 Recursive Pruning이 각 단계마다 성능을 세밀하게 복구하기 때문이다.

결론적으로, One-shot Pruning은 빠르고 단순한 경량화에 적합하며, Recursive Pruning은 성능 유지와 안정성이 중요한 상황에서 더 효과적이다. 모델의 특성과 사용 환경에 따라 적절한 방식을 선택하는 것이 중요하다. One-shot Pruning은 속도를, Recursive Pruning은 안정성을 중점으로 한다.
Initalizer
Pruning 후, Fine-tuning 또는 추가 학습을 진행할 때, 파라미터를 어떤 상태로 초기화할지 결정하는 것은 성능 복구와 최종 모델의 품질에 큰 영향을 미친다. 이를 Initialization이라 하며, 크게 두 가지 방법으로 나뉜다: Weight-preserving과 Weight-reinitializing이다.
1. Weight-preserving (클래식 방식)
Weight-preserving 방식은 Pruning 후 남아있는 파라미터 값을 그대로 유지한 채 Fine-tuning을 진행하는 방법이다.
이 방식은 기존의 학습된 정보가 유지되므로, 추가 학습을 빠르게 진행할 수 있고 성능 복구도 안정적이다.
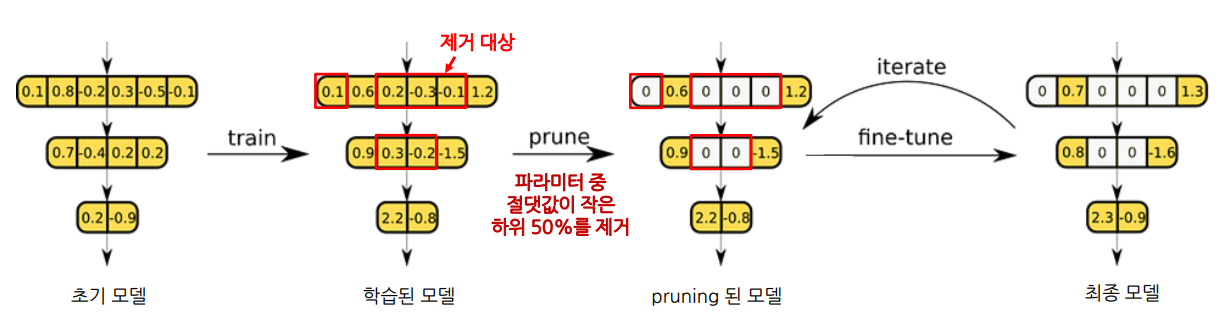
Pruning 전 학습된 모델에서, 중요도가 낮은 파라미터를 제거하고 남아있는 파라미터를 초기 값으로 유지한다.
이후 Fine-tuning 과정을 통해 모델의 성능을 복구하며, 경량화된 모델에서도 원래 모델과 유사한 성능을 달성할 수 있다.
2. Weight-reinitializing (Rewinding 방식)
Weight-reinitializing 방식은 Pruning 후 남아있는 파라미터를 무작위로 초기화한 뒤, 모델을 처음부터 다시 학습하는 방법이다.이는 기존 학습 정보를 초기화함으로써, 프루닝 후 모델이 새로운 구조에 적응할 기회를 제공한다.

Pruning 된 모델에서 남아있는 파라미터를 랜덤 값으로 다시 설정하고, 모델을 처음부터 재학습한다.
이 방식은 기존 학습 정보에 의존하지 않으므로, 프루닝 후 과적합 문제가 발생할 가능성을 줄인다.
결론
Weight-reinitializing은 새로운 구조에 맞게 모델을 처음부터 다시 학습하는 방식이기 때문에, 학습 시간이 Weight-preserving보다 훨씬 오래 걸린다.
따라서, 학습 시간이 중요한 상황에서는 Weight-preserving 방식을 선택하는 것이 더 적합하며, Weight-reinitializing은 시간이 더 걸리더라도 성능 최적화가 필요한 경우에 적합하다.
IMP (Iterative Magnitude Pruning)
Iterative Magnitude Pruning은 가장 기본적인 Pruning 방법 중 하나로, 모델의 가중치 크기를 기준으로 중요도를 평가하고 반복적으로 프루닝을 수행하는 방식이다.
- Structure:
- Unstructured Pruning 방식을 사용하여 개별 가중치를 제거한다.
- Scoring:
- 가중치의 절댓값을 기준으로 중요도를 측정한다.
- Global Pruning을 통해 모델 전체에서 중요도를 계산하고 제거한다.
- Scheduling:
- Pruning과 Fine-tuning을 반복적으로 수행하는 Recursive 방식을 채택한다.
- Initialization:
- Pruning 후, Rewind 방식을 활용하여 남은 파라미터를 초기화한 뒤 재학습을 진행한다.
위의 방법들로 구성된 Pruning 방법이다.
그림으로 이해해보면 아래와 같다.


이상입니다. 끝.
다음에는 Pruning 을 간단한 코드로 구현해서 소개하겠습니다.
감사합니다.
'딥러닝 (Deep Learning) > [04] - 학습 및 최적화' 카테고리의 다른 글
| [Optimizer] - 초기 optimizer 이해 [1] (3) | 2024.12.28 |
|---|---|
| [경량화/최적화] - 레이버별 민감도 기반 Pruning [3] (2) | 2024.12.24 |
| [경량화/최적화] - Pruning 이란? [1] (1) | 2024.12.23 |
| Pseudo 라벨링(Pseudo Labeling)이란 무엇인가? (0) | 2024.11.24 |
| 딥러닝 학습률(Learning Rate) 종류와 설정 방법 (1) | 2024.11.17 |